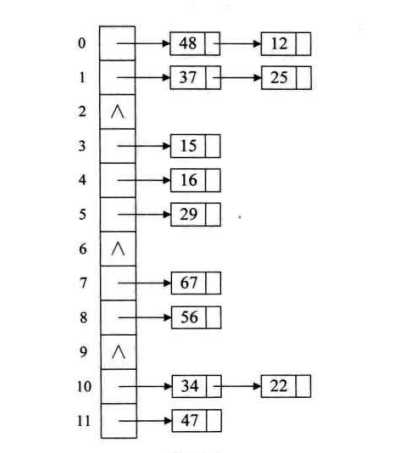
哈希表
# 概念
哈希表(Hash Table)也称散列表,是根据关键码值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
也就是说每个记录都以 key-value 的形式存储,通过 key 计算 value 的函数是散列函数,而且 key 是不可重复的。
如为了查找电话本中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 x 到首字母 F(x)的一个函数关系),在首字母为 W 的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中的散列函数,存放首字母的表就是散列表。
# 特点
顺序表的特点是容易查找,但是不适合插入和删除;而链表的特点是插入和删除容易,但是不适合查找。散列表就是顺序表和链表之间做了折中,适合查找,也降低了插入和删除的时间复杂度。
# 散列函数
散列函数没有具体的算法,大都是根据具体业务场景自行设计的,比如前面提到的取首字母就是一种。但是在设计散列函数的时候需要注意两点:
- 散列函数要尽可能简单。
- 散列函数计算的结果要分布均匀,避免倾斜。
常用的哈希函数的构造方法有 6 种:
# 直接定址法
直接定址法就是取关键字的某个线性函数作为散列地址,即:f(key) = a * key + b (a 和 b 均为常数)
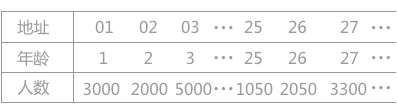
如图,若需要查找年龄为 25 岁的人口数量,将年龄 25 带入哈希函数中,直接求得其对应的哈希地址为 25,对应的值为 1050。
# 数字分析法
若关键字是位数较多的数字组成,则可以考虑抽取其中多位分布均匀的数字作为散列地址。如身份证号码后四位或后六位。
# 平方取中法
对关键字做平方操作,取中间得几位作为哈希地址。假设关键字是 1234,其平方数为 1522756,再抽取其中间 3 为 227 作为散列地址。
# 折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。如关键字是 9876543210,散列表表长为 3 为,将其分为 4 组,987|654|321|0,然后叠加求和 987 + 654+321+0 = 1962,再求最后三位得到散列地址为 962。
# 除留余数法
若已知整个哈希表的最大长度 m,可以取一个不大于 m 的数 p,然后对该关键字 key 做取余运算,即:f(key) = key % p。
除留余数法是用的最多的散列函数,一般会先求 key 的 hashCode,然后对 hashCode 进行取余。
# 随机数法
取关键字的随机函数值作为散列地址,即 f(key) = random(key)。
# 散列冲突