Spark 存储体系源码分析
提示
以下内容基于 Spark 3.0.0。
Hadoop 中会将中间计算结果写入磁盘中,Spark 为了避免磁盘读写带来的 IO 消耗,会优先将计算结果以及其它信息存储到内存中,只有达到溢写条件的数据才会写入磁盘中,这极大地提高了 Spark 的执行效率。所以 Spark 存储体系应该包含两部分:内存和磁盘。
Spark 中对内存和磁盘的管理是由 BlockManager 代为进行的,BlockManager 存在于 Driver 以及每个 Executor 中,它是 Spark 存储体系的核心。
# 1. 基本概念
# 1.1 Block
Spark 中用 Block(块)表示最小的数据读写单位。在源码中关于 Block 的实现是 BlockData,BlockData 抽象了 Block
的存储方式,并提供了不同的方式来读取底层块数据。调用者在使用完 Block 会调用 dispose()方法。其源码实现如下:
private[spark] trait BlockData {
def toInputStream(): InputStream
def toNetty(): Object
def toChunkedByteBuffer(allocator: Int => ByteBuffer): ChunkedByteBuffer
def toByteBuffer(): ByteBuffer
def size: Long
def dispose(): Unit
}
2
3
4
5
6
7
8
9
10
11
12
13
14
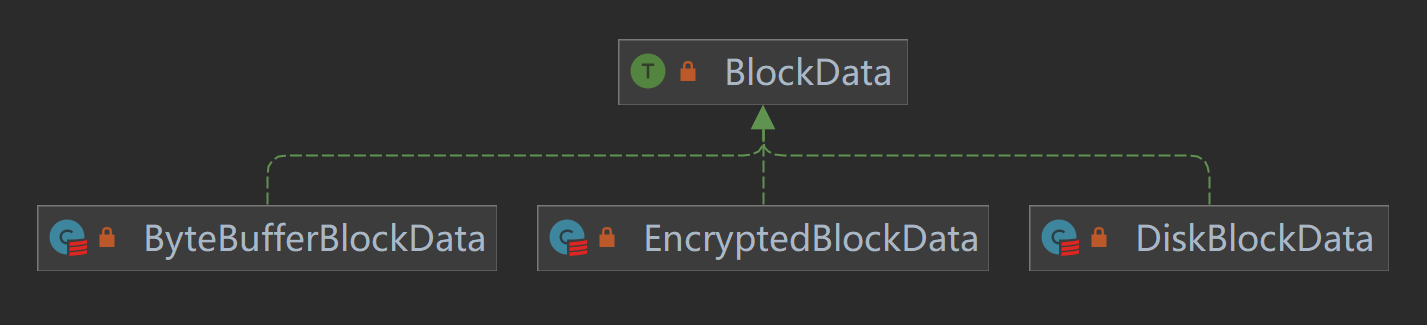
BlockData 是一个 trait,其定义了一系列对 Block 的操作,其有三个具体的实现类,继承关系如下:
# 1.2 BlockId
BlockId 是用来唯一标识一个 Block 的抽象。BlockId 源码及其实现源码如下:
点击查看
sealed abstract class BlockId {
def name: String
def asRDDId: Option[RDDBlockId] = if (isRDD) Some(asInstanceOf[RDDBlockId]) else None
def isRDD: Boolean = isInstanceOf[RDDBlockId]
def isShuffle: Boolean = isInstanceOf[ShuffleBlockId] || isInstanceOf[ShuffleBlockBatchId]
def isBroadcast: Boolean = isInstanceOf[BroadcastBlockId]
override def toString: String = name
}
case class RDDBlockId(rddId: Int, splitIndex: Int) extends BlockId {
override def name: String = "rdd_" + rddId + "_" + splitIndex
}
case class ShuffleBlockId(shuffleId: Int, mapId: Long, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId
}
case class ShuffleBlockBatchId(
shuffleId: Int,
mapId: Long,
startReduceId: Int,
endReduceId: Int) extends BlockId {
override def name: String = {
"shuffle_" + shuffleId + "_" + mapId + "_" + startReduceId + "_" + endReduceId
}
}
case class ShuffleDataBlockId(shuffleId: Int, mapId: Long, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId + ".data"
}
case class ShuffleIndexBlockId(shuffleId: Int, mapId: Long, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId + ".index"
}
case class BroadcastBlockId(broadcastId: Long, field: String = "") extends BlockId {
override def name: String = "broadcast_" + broadcastId + (if (field == "") "" else "_" + field)
}
case class TaskResultBlockId(taskId: Long) extends BlockId {
override def name: String = "taskresult_" + taskId
}
case class StreamBlockId(streamId: Int, uniqueId: Long) extends BlockId {
override def name: String = "input-" + streamId + "-" + uniqueId
}
private[spark] case class TempLocalBlockId(id: UUID) extends BlockId {
override def name: String = "temp_local_" + id
}
private[spark] case class TempShuffleBlockId(id: UUID) extends BlockId {
override def name: String = "temp_shuffle_" + id
}
private[spark] case class TestBlockId(id: String) extends BlockId {
override def name: String = "test_" + id
}
class UnrecognizedBlockId(name: String)
extends SparkException(s"Failed to parse $name into a block ID")
object BlockId {
val RDD = "rdd_([0-9]+)_([0-9]+)".r
val SHUFFLE = "shuffle_([0-9]+)_([0-9]+)_([0-9]+)".r
val SHUFFLE_BATCH = "shuffle_([0-9]+)_([0-9]+)_([0-9]+)_([0-9]+)".r
val SHUFFLE_DATA = "shuffle_([0-9]+)_([0-9]+)_([0-9]+).data".r
val SHUFFLE_INDEX = "shuffle_([0-9]+)_([0-9]+)_([0-9]+).index".r
val BROADCAST = "broadcast_([0-9]+)([_A-Za-z0-9]*)".r
val TASKRESULT = "taskresult_([0-9]+)".r
val STREAM = "input-([0-9]+)-([0-9]+)".r
val TEMP_LOCAL = "temp_local_([-A-Fa-f0-9]+)".r
val TEMP_SHUFFLE = "temp_shuffle_([-A-Fa-f0-9]+)".r
val TEST = "test_(.*)".r
def apply(name: String): BlockId = name match {
case RDD(rddId, splitIndex) =>
RDDBlockId(rddId.toInt, splitIndex.toInt)
case SHUFFLE(shuffleId, mapId, reduceId) =>
ShuffleBlockId(shuffleId.toInt, mapId.toLong, reduceId.toInt)
case SHUFFLE_BATCH(shuffleId, mapId, startReduceId, endReduceId) =>
ShuffleBlockBatchId(shuffleId.toInt, mapId.toLong, startReduceId.toInt, endReduceId.toInt)
case SHUFFLE_DATA(shuffleId, mapId, reduceId) =>
ShuffleDataBlockId(shuffleId.toInt, mapId.toLong, reduceId.toInt)
case SHUFFLE_INDEX(shuffleId, mapId, reduceId) =>
ShuffleIndexBlockId(shuffleId.toInt, mapId.toLong, reduceId.toInt)
case BROADCAST(broadcastId, field) =>
BroadcastBlockId(broadcastId.toLong, field.stripPrefix("_"))
case TASKRESULT(taskId) =>
TaskResultBlockId(taskId.toLong)
case STREAM(streamId, uniqueId) =>
StreamBlockId(streamId.toInt, uniqueId.toLong)
case TEMP_LOCAL(uuid) =>
TempLocalBlockId(UUID.fromString(uuid))
case TEMP_SHUFFLE(uuid) =>
TempShuffleBlockId(UUID.fromString(uuid))
case TEST(value) =>
TestBlockId(value)
case _ =>
throw new UnrecognizedBlockId(name)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
# 1.3 BlockInfo
BlockInfo 是用来描述 Block 的元数据。具体包括 Block 大小、存储级别、Block 类型、被读取的次数以及锁信息等。源码如下:
点击查看
private[storage] class BlockInfo(
// 存储级别
val level: StorageLevel,
// BlockInfo 所描述的 Block 类型
val classTag: ClassTag[_],
// 是否需要告知 Master
val tellMaster: Boolean) {
// Block 大小(bytes)
def size: Long = _size
def size_=(s: Long): Unit = {
_size = s
checkInvariants()
}
private[this] var _size: Long = 0
// 该 Block 被读取的次数
def readerCount: Int = _readerCount
def readerCount_=(c: Int): Unit = {
_readerCount = c
checkInvariants()
}
private[this] var _readerCount: Int = 0
// 持有当前 Block 写锁的任务尝试 ID
def writerTask: Long = _writerTask
def writerTask_=(t: Long): Unit = {
_writerTask = t
checkInvariants()
}
private[this] var _writerTask: Long = BlockInfo.NO_WRITER
private def checkInvariants(): Unit = {
assert(_readerCount >= 0)
assert(_readerCount == 0 || _writerTask == BlockInfo.NO_WRITER)
}
checkInvariants()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 2. 存储体系架构
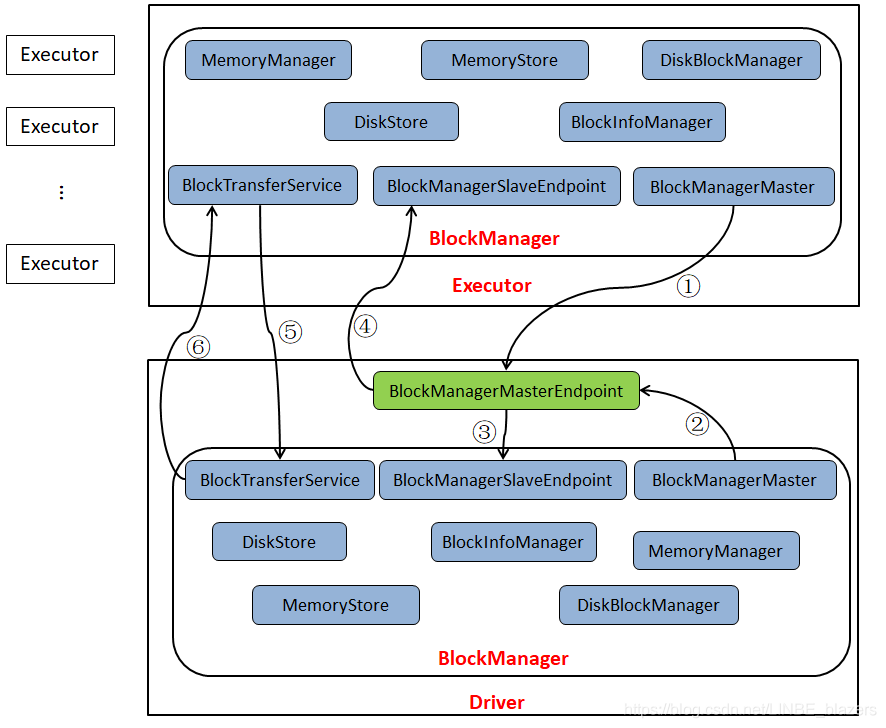
Spark 存储体系的宏观架构如下:
提示
如果对下面提到的“引用”不理解,请先阅读Spark RPC 通信。
- BlockManager:BlockManager 是存储体系最核心的组件,它存在于 Spark 中的所有结点中(包括 Driver 和 Executor),BlockManager 的核心功能就是对磁盘、堆内存和堆外内存进行统一管理。
- BlockManagerMasterEndpoint:由 Driver 中的 SparkEnv 创建,且只存在于 Driver 中。它的作用是对各个节点上的 BlockManager 以及 BlockManager 与 Executor 的映射关系和 Block 位置信息进行管理。Driver 和 Executor 中的 BlockManager 中的 BlockManagerMaster 持有 BlockManagerMasterEndpoint 的引用,所以 Driver 和 Executor 中的 BlockManger 可以通过该引用对 BlockManagerMasterEndpoint 发送消息。
- BlockManagerSlaveEndpoint:每个 BlockManager 中都有 BlockManagerSlaveEndpoint 组件,而且 BlockManager 的 slaveEndpoint 属性持有 BlockManagerSlaveEndpoint 的引用。由于 BlockManagerMasterEndpoint 中维护了 BlockManager 信息,BlockManager 又持有 BlockManagerSlaveEndpoint 的引用,所以 BlockManagerMasterEndpoint 可以通过该引用对 BlockManagerSlaveEndpoint 发送消息。
- BlockManagerMaster:BlockManagerMaster 持有 BlockManagerMasterEndpoint 的引用。Driver 与 Executor 中的 BlockManager 信息交互都需要依赖于 BlockManagerMaster。
- BlockInfoManager:BlockInfo 是 Block 元数据的表示,BlockInfoManager 顾名思义就是负责对 Block 元数据进行管理。
- BlockTransferService:块传输服务。主要用于不同阶段任务之间的 Block 传输与读写。
- MemoryManager:内存管理器。负责节点内存的分配与回收。
- MemoryStore:负责 Block 在内存中的存储。
- DiskBlockManager:磁盘块管理器。对磁盘上的读写操作进行管理。
- DiskStore:负责 Block 在磁盘中的存储。
上图中列出的是 BlockManager 的核心组件,实际上 BlockManager 的功能是非常庞大的(Spark 3.0.0 中的源码就有 1800 行),除了上述组件之外还有 SerializerManager、MapOutputTracker、ShuffleManager、SecurityManager 等组件。
# 2.1 BlockManagerMasterEndpoint
BlockManagerMasterEndpoint 是在只存在于 Driver 上的组件,是 RpcEndpoint 的子类。它的主要作用是跟踪所有 BlockManager 的状态,并对其统一管理。BlockManagerMasterEndpoint 的结构如下,由于代码太长所以放个截图:
其核心属性如下:
// 维护了BlockManagerId 与 BlockManagerInfo 的映射关系
blockManagerInfo: mutable.Map[BlockManagerId, BlockManagerInfo]
// 维护了 ExecutorId 与 BlockManagerId 之间的映射关系
blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
// 维护了 BlockId 与 存储此 BlockId 的 BlockManager 的 BlockManagerId 之间的映射关系
blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
2
3
4
5
6
7
8
由于 BlockManagerMasterEndpoint 是 RpcEndpoint 的子类,所以其重写了 receiveAndReply 方法,用于接收并处理来自 BlockManager 的消息,receiveAndReply 也是 BlockManagerMasterEndpoint 最核心的方法。源码如下:
点击查看
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterBlockManager(id, localDirs, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint) =>
context.reply(register(id, localDirs, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint))
case _updateBlockInfo@
UpdateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size) =>
val isSuccess = updateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size)
context.reply(isSuccess)
// SPARK-30594: we should not post `SparkListenerBlockUpdated` when updateBlockInfo
// returns false since the block info would be updated again later.
if (isSuccess) {
listenerBus.post(SparkListenerBlockUpdated(BlockUpdatedInfo(_updateBlockInfo)))
}
case GetLocations(blockId) =>
context.reply(getLocations(blockId))
case GetLocationsAndStatus(blockId, requesterHost) =>
context.reply(getLocationsAndStatus(blockId, requesterHost))
case GetLocationsMultipleBlockIds(blockIds) =>
context.reply(getLocationsMultipleBlockIds(blockIds))
case GetPeers(blockManagerId) =>
context.reply(getPeers(blockManagerId))
case GetExecutorEndpointRef(executorId) =>
context.reply(getExecutorEndpointRef(executorId))
case GetMemoryStatus =>
context.reply(memoryStatus)
case GetStorageStatus =>
context.reply(storageStatus)
case GetBlockStatus(blockId, askSlaves) =>
context.reply(blockStatus(blockId, askSlaves))
case IsExecutorAlive(executorId) =>
context.reply(blockManagerIdByExecutor.contains(executorId))
case GetMatchingBlockIds(filter, askSlaves) =>
context.reply(getMatchingBlockIds(filter, askSlaves))
case RemoveRdd(rddId) =>
context.reply(removeRdd(rddId))
case RemoveShuffle(shuffleId) =>
context.reply(removeShuffle(shuffleId))
case RemoveBroadcast(broadcastId, removeFromDriver) =>
context.reply(removeBroadcast(broadcastId, removeFromDriver))
case RemoveBlock(blockId) =>
removeBlockFromWorkers(blockId)
context.reply(true)
case RemoveExecutor(execId) =>
removeExecutor(execId)
context.reply(true)
case StopBlockManagerMaster =>
context.reply(true)
stop()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
可以看到 BlockManagerMasterEndpoint 接收的 BlockManager 消息包括:
- RegisterBlockManager:注册 BlockManager。
- UpdateBlockInfo:更新 Block 信息。
- GetLocations:获取 Block 位置。
- GetLocationsAndStatus:同时获取 Block 位置和状态。
- GetLocationsMultipleBlockIds:获取多个 Block 位置。
- GetPeers:获取其它 BlockManager 的 BlockManagerId。
- GetExecutorEndpointRef:获取 Executor Endpoint 的引用。
- GetMemoryStatus:获取指定 BlockManager 的内存状态。
- GetStorageStatus:获取存储状态。
- GetBlockStatus:获取 Block 状态。
- IsExecutorAlive:获取 Executor 是否存活的信息。
- GetMatchingBlockIds:获取匹配过滤条件的 Block。
- RemoveRdd:移除属于给定 rddId 的所有 Rdd Block。
- RemoveShuffle:移除属于给定 shuffleId 的所有 Block。
- RemoveBroadcast:移除属于给定 broadcastId 的所有 Block。
- RemoveBlock:移除给定 blockId 的 Block。
- RemoveExecutor:移除 Executor。
- StopBlockManagerMaster:停止 BlockManagerMaster。
BlockManagerMasterEndpoint 除了可以接收 来自 BlockManager 的消息,同时也可以对 BlockManager 发送消息,发送的消息类型包括:
- RemoveBlock:移除给定 blockId 的 Block。
- RemoveRdd:移除属于给定 rddId 的所有 Rdd Block。
- RemoveShuffle:移除属于给定 shuffleId 的所有 Block。
- RemoveBroadcast:移除属于给定 broadcastId 的所有 Block。
- ReplicateBlock:复制由于 Executor 故障而丢失的 Block。
- TriggerThreadDump:Driver 通知 Executor 触发 thread dump。
无论是 BlockManagerMasterEndpoint 接收的消息还是发送给 BlockManager 的消息,其实现都是 case class,源码如下:
点击查看
private[spark] object BlockManagerMessages {
//////////////////////////////////////////////////////////////////////////////////
// Messages from the master to slaves.
//////////////////////////////////////////////////////////////////////////////////
sealed trait ToBlockManagerSlave
case class RemoveBlock(blockId: BlockId) extends ToBlockManagerSlave
case class ReplicateBlock(blockId: BlockId, replicas: Seq[BlockManagerId], maxReplicas: Int) extends ToBlockManagerSlave
case class RemoveRdd(rddId: Int) extends ToBlockManagerSlave
case class RemoveShuffle(shuffleId: Int) extends ToBlockManagerSlave
case class RemoveBroadcast(broadcastId: Long, removeFromDriver: Boolean = true) extends ToBlockManagerSlave
case object TriggerThreadDump extends ToBlockManagerSlave
//////////////////////////////////////////////////////////////////////////////////
// Messages from slaves to the master.
//////////////////////////////////////////////////////////////////////////////////
sealed trait ToBlockManagerMaster
case class RegisterBlockManager(
blockManagerId: BlockManagerId,
localDirs: Array[String],
maxOnHeapMemSize: Long,
maxOffHeapMemSize: Long,
sender: RpcEndpointRef)
extends ToBlockManagerMaster
case class UpdateBlockInfo(
var blockManagerId: BlockManagerId,
var blockId: BlockId,
var storageLevel: StorageLevel,
var memSize: Long,
var diskSize: Long)
extends ToBlockManagerMaster
with Externalizable {
def this() = this(null, null, null, 0, 0) // For deserialization only
override def writeExternal(out: ObjectOutput): Unit = Utils.tryOrIOException {
blockManagerId.writeExternal(out)
out.writeUTF(blockId.name)
storageLevel.writeExternal(out)
out.writeLong(memSize)
out.writeLong(diskSize)
}
override def readExternal(in: ObjectInput): Unit = Utils.tryOrIOException {
blockManagerId = BlockManagerId(in)
blockId = BlockId(in.readUTF())
storageLevel = StorageLevel(in)
memSize = in.readLong()
diskSize = in.readLong()
}
}
case class GetLocations(blockId: BlockId) extends ToBlockManagerMaster
case class GetLocationsAndStatus(blockId: BlockId, requesterHost: String) extends ToBlockManagerMaster
case class BlockLocationsAndStatus(
locations: Seq[BlockManagerId],
status: BlockStatus,
localDirs: Option[Array[String]]) {
assert(locations.nonEmpty)
}
case class GetLocationsMultipleBlockIds(blockIds: Array[BlockId]) extends ToBlockManagerMaster
case class GetPeers(blockManagerId: BlockManagerId) extends ToBlockManagerMaster
case class GetExecutorEndpointRef(executorId: String) extends ToBlockManagerMaster
case class RemoveExecutor(execId: String) extends ToBlockManagerMaster
case object StopBlockManagerMaster extends ToBlockManagerMaster
case object GetMemoryStatus extends ToBlockManagerMaster
case object GetStorageStatus extends ToBlockManagerMaster
case class GetBlockStatus(blockId: BlockId, askSlaves: Boolean = true) extends ToBlockManagerMaster
case class GetMatchingBlockIds(filter: BlockId => Boolean, askSlaves: Boolean = true) extends ToBlockManagerMaster
case class BlockManagerHeartbeat(blockManagerId: BlockManagerId) extends ToBlockManagerMaster
case class IsExecutorAlive(executorId: String) extends ToBlockManagerMaster
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
除了 receiveAndReply 方法,其它方法通过方法名结合消息名称就可以看出来是为 receiveAndReply 服务的,或者说是对 receiveAndReply 中 match 到一种消息之后工作的提炼包装。从 BlockManagerMasterEndpoint 的结构可以进一步确认它的职责,就是为了统一管理 BlockManager。
BlockManagerMasterEndpoint 既然在接受消息的同时可以发送消息,那发送消息的代码在哪里呢?发送的逻辑其实也内嵌是在 receiveAndReply 中的。比如 receiveAndReply 中针对 removeShuffle 消息的请求会调用 removeShuffle 方法,removeShuffle 方法的源码如下:
private def removeShuffle(shuffleId: Int): Future[Seq[Boolean]] = {
// 包装 RemoveShuffle 消息,然后将该消息发送给所有的 BlockManager
val removeMsg = RemoveShuffle(shuffleId)
Future.sequence(
blockManagerInfo.values.map { bm =>
// 这里使用的 ask 方法,当 BlockManagerSlaveEndpoint 收到消息后,会调用自己的 receiveAndReply 方法进行处理
bm.slaveEndpoint.ask[Boolean](removeMsg)
}.toSeq
)
}
2
3
4
5
6
7
8
9
10
# 2.2 BlockManagerSlaveEndpoint
每个 BlockManager 中都有 BlockManagerSlaveEndpoint,它主要接受来自 BlockManagerMasterEndpoint 的消息,并执行相应的处理。源码如下:
点击查看
private[storage] class BlockManagerSlaveEndpoint(
override val rpcEnv: RpcEnv,
blockManager: BlockManager,
mapOutputTracker: MapOutputTracker)
extends IsolatedRpcEndpoint with Logging {
private val asyncThreadPool =
ThreadUtils.newDaemonCachedThreadPool("block-manager-slave-async-thread-pool", 100)
private implicit val asyncExecutionContext = ExecutionContext.fromExecutorService(asyncThreadPool)
// Operations that involve removing blocks may be slow and should be done asynchronously
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RemoveBlock(blockId) =>
doAsync[Boolean]("removing block " + blockId, context) {
blockManager.removeBlock(blockId)
true
}
case RemoveRdd(rddId) =>
doAsync[Int]("removing RDD " + rddId, context) {
blockManager.removeRdd(rddId)
}
case RemoveShuffle(shuffleId) =>
doAsync[Boolean]("removing shuffle " + shuffleId, context) {
if (mapOutputTracker != null) {
mapOutputTracker.unregisterShuffle(shuffleId)
}
SparkEnv.get.shuffleManager.unregisterShuffle(shuffleId)
}
case RemoveBroadcast(broadcastId, _) =>
doAsync[Int]("removing broadcast " + broadcastId, context) {
blockManager.removeBroadcast(broadcastId, tellMaster = true)
}
case GetBlockStatus(blockId, _) =>
context.reply(blockManager.getStatus(blockId))
case GetMatchingBlockIds(filter, _) =>
context.reply(blockManager.getMatchingBlockIds(filter))
case TriggerThreadDump =>
context.reply(Utils.getThreadDump())
case ReplicateBlock(blockId, replicas, maxReplicas) =>
context.reply(blockManager.replicateBlock(blockId, replicas.toSet, maxReplicas))
}
private def doAsync[T](actionMessage: String, context: RpcCallContext)(body: => T): Unit = {
val future = Future {
logDebug(actionMessage)
body
}
future.foreach { response =>
logDebug(s"Done $actionMessage, response is $response")
context.reply(response)
logDebug(s"Sent response: $response to ${context.senderAddress}")
}
future.failed.foreach { t =>
logError(s"Error in $actionMessage", t)
context.sendFailure(t)
}
}
override def onStop(): Unit = {
asyncThreadPool.shutdownNow()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
BlockManagerSlaveEndpoint 中最核心的方法同样是 receiveAndReply,对于消息的处理也是通过模式匹配进行的,可处理消息包括:
- RemoveBlock:移除给定 blockId 的 Block。
- RemoveRdd:移除属于给定 rddId 的所有 Rdd Block。
- RemoveShuffle:移除属于给定 shuffleId 的所有 Block。
- RemoveBroadcast:移除属于给定 broadcastId 的所有 Block。
- ReplicateBlock:复制由于 Executor 故障而丢失的 Block。
- TriggerThreadDump:Driver 通知 Executor 触发 thread dump。
# 2.3 BlockManagerMaster
BlockManagerMaster 的 driverEndpoint 属性持有 BlockManagerMasterEndpoint 的引用,可以通过该引用代替 BlockManager 向 BlockManagerMasterEndpoint 发送消息。BlockManagerMaster 的结构如下:
BlockManagerMaster 中所有的方法实现都是为发送消息而生的,如:
// 注册 BlockManager
def registerBlockManager(id: BlockManagerId, localDirs: Array[String], maxOnHeapMemSize: Long, maxOffHeapMemSize: Long, slaveEndpoint: RpcEndpointRef): BlockManagerId = {
logInfo(s"Registering BlockManager $id")
val updatedId = driverEndpoint.askSync[BlockManagerId](RegisterBlockManager(id, localDirs, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint))
logInfo(s"Registered BlockManager $updatedId")
updatedId
}
def updateBlockInfo(blockManagerId: BlockManagerId, blockId: BlockId, storageLevel: StorageLevel, memSize: Long, diskSize: Long): Boolean = {
val res = driverEndpoint.askSync[Boolean](UpdateBlockInfo(blockManagerId, blockId, storageLevel, memSize, diskSize))
logDebug(s"Updated info of block $blockId")
res
}
2
3
4
5
6
7
8
9
10
11
12
13
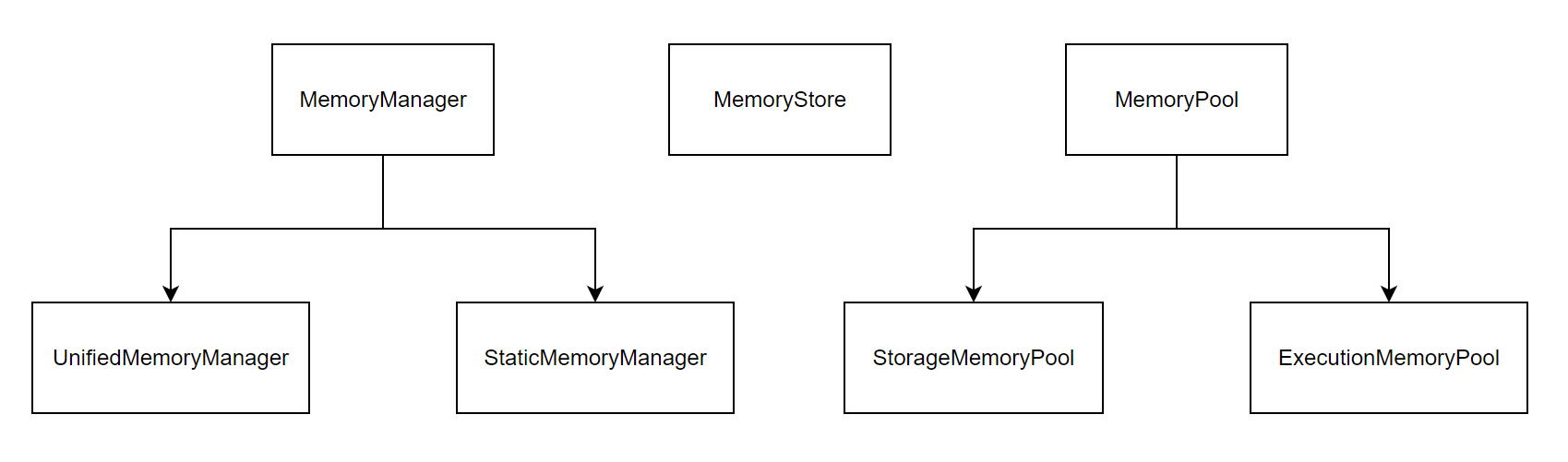
# 3. 内存管理
Spark 内存管理的核心类如下:
# 3.1 内存模型
# 3.1.1 堆内内存 & 堆外内存
Spark 中的内存从逻辑上可以分为堆内内存和堆外内存,源码中使用枚举类表示:
public enum MemoryMode {
ON_HEAP, OFF_HEAP
}
2
3
堆内内存
这里的堆内内存并不完全等同于 JVM 里的堆内存,而是比 JVM 堆内存更小的单元。因为 Driver 和 Executor 都是一个 JVM 进程,所以
Driver 和 Executor 的内存管理是建立在 JVM 堆内存之上的,所以这里的堆内内存实际上是对 JVM 堆内存做了更细的分配。在提交
Spark 任务时通过--driver-memory、spark.driver.memory、-–executor-memory、spark.executor.memory指定就是堆内内存。由于
Driver 只负责创建 SparkContext、提交 Job 以及 Task 划分,所以 Driver 的内存管理和普通的 JVM 相近。而 Executor
则要负责具体的计算任务,所以 Executor 的内存管理是需要重点关注的,后续的内容也是针对 Executor 内存管理进行的。
堆内内存的优缺点:
- 堆内内存采用 JVM 来进行管理。而 JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。
- 对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算。
- 对于 Spark 中非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小。这种方式降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
堆外内存
堆外内存就是在系统内存中开辟的空间,独立于 JVM。Spark 自 1.6
引入了堆外内存的概念(详见SPARK-11389 (opens new window)),直接调用 Java sun.misc.Unsafe 相关
API 直接在工作节点的系统内存中开辟空间。
堆外内存的优缺点分析:
- 直接在系统中开辟内存,可以避免频繁的 GC。
- 需要自己编写内存申请和释放的逻辑。
- 可以精准控制内存开销,相对堆内内存来说降低了误差。
# 3.1.2 存储内存 & 执行内存
从用途上可以分为 Storage Memory(存储内存,用于跨集群缓存和传播内部数据)和 Execution Memory(执行内存,用于诸如 shuffle、join、sort 以及聚合之类的数据计算)。所以 Spark 逻辑上应该包含四块内存:
- 堆内存储内存
- 堆外存储内存
- 堆内执行内存
- 堆外执行内存
实际上在 MemoryManager 源码中也是定义了对应的四个内存池:
// 堆内存储内存
protected val onHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.ON_HEAP)
// 堆外存储内存
protected val offHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.OFF_HEAP)
// 堆内执行内存
protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.ON_HEAP)
// 堆外执行内存
protected val offHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.OFF_HEAP)
2
3
4
5
6
7
8
# 3.2 内存池
看名字感觉高大上以为用了什么池化技术,实际上就是一个备忘录,或者类似于记事本的功能,只是实现了记录内存使用情况的功能。当申请内存时,Spark 保存了对象的引用,并记录该对象占用的内存,增加已使用内存;当释放内存时,Spark 从记录的已使用内存中减去该对象占用的内存,然后删除该对象的引用。
Spark 中内存池的实现是MemoryPool,它是一个抽象类。实质上是对物理内存的逻辑规划,协助 Spark
任务在运行时合理地使用内存资源。MemoryPool有两个实现类:StorageMemoryPool和ExecutionMemoryPool,分别负责对存储内存和执行内存的规划。
ExecutionMemoryPool 会尝试确保每个 task 获得合理的内存份额,而不是一些 task 首先增加到大量内存,然后导致其它 task
重复溢写到磁盘。如果有 N 个任务,会确保每个任务在溢出之前可以获得至少 1 / 2N、最多 1 / N 的内存。因为 N
是动态变化的,ExecutionMemoryPool会跟踪处于 active 状态的 task 集合,并在此集合发生变化时为每个 task 重新分配内存。
MemoryPool 源码如下:
点击查看
// lock 是一个锁对象,用以保证对内存大小的修改是线程安全的
// 此处声明为 Object 类型,实际就是 MemoryManager 对象
private[memory] abstract class MemoryPool(lock: Object) {
// 内存池总大小,单位为字节
@GuardedBy("lock")
private[this] var _poolSize: Long = 0
// 返回内存池总大小
final def poolSize: Long = lock.synchronized {
_poolSize
}
// 返回未使用的内存大小
final def memoryFree: Long = lock.synchronized {
_poolSize - memoryUsed
}
// 为内存池扩展 delta 字节
final def incrementPoolSize(delta: Long): Unit = lock.synchronized {
require(delta >= 0)
_poolSize += delta
}
// 为内存池缩小 delta 字节
final def decrementPoolSize(delta: Long): Unit = lock.synchronized {
require(delta >= 0)
require(delta <= _poolSize)
require(_poolSize - delta >= memoryUsed)
_poolSize -= delta
}
// 返回使用的内存大小,单位为字节
def memoryUsed: Long
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 3.2.1 StorageMemoryPool
源码如下:
点击查看
// lock 是用于保证线程安全的锁对象,实际上是 MemoryManager 的实例
// memoryMode 标识内存模式为堆内内存还是堆外内存
private[memory] class StorageMemoryPool(
lock: Object,
memoryMode: MemoryMode
) extends MemoryPool(lock) with Logging {
// 内存池名称
private[this] val poolName: String = memoryMode match {
case MemoryMode.ON_HEAP => "on-heap storage"
case MemoryMode.OFF_HEAP => "off-heap storage"
}
// 使用的内存
@GuardedBy("lock")
private[this] var _memoryUsed: Long = 0L
override def memoryUsed: Long = lock.synchronized {
_memoryUsed
}
// 当前内存池关联的 MemoryStore 对象,MemoryStore 是负责 Block 在内存中存储的组件
private var _memoryStore: MemoryStore = _
def memoryStore: MemoryStore = {
if (_memoryStore == null) {
throw new IllegalStateException("memory store not initialized yet")
}
_memoryStore
}
final def setMemoryStore(store: MemoryStore): Unit = {
_memoryStore = store
}
// 获取 numBytes 字节的内存来缓存给定的 Block,必要时移除现有的 Block
def acquireMemory(blockId: BlockId, numBytes: Long): Boolean = lock.synchronized {
// 如果 numBytesToFree 大于 0,则说明 numBytes(需要申请的内存) > memoryFree(空闲内存)
// 所以需要通过移除现有 Block 来腾出 numBytesToFree 大小的内存
val numBytesToFree = math.max(0, numBytes - memoryFree)
acquireMemory(blockId, numBytes, numBytesToFree)
}
// 获取 N 字节的内存来缓存给定的 Block,必要时移除现有的 Block
def acquireMemory(
blockId: BlockId, // 为当前 blockId 表示的 Block 申请存储内存
numBytesToAcquire: Long, // 当前 blockId 表示的 Block 大小
numBytesToFree: Long // 需要通过移除现有 Block 释放的内存大小
): Boolean = lock.synchronized {
assert(numBytesToAcquire >= 0)
assert(numBytesToFree >= 0)
assert(memoryUsed <= poolSize)
// 通过 MemoryStore 释放 numBytesToFree 大小的内存
if (numBytesToFree > 0) {
memoryStore.evictBlocksToFreeSpace(Some(blockId), numBytesToFree, memoryMode)
}
// NOTE: If the memory store evicts blocks, then those evictions will synchronously call
// back into this StorageMemoryPool in order to free memory. Therefore, these variables
// should have been updated.
val enoughMemory = numBytesToAcquire <= memoryFree
if (enoughMemory) {
_memoryUsed += numBytesToAcquire
}
enoughMemory
}
// 释放指定大小的内存
def releaseMemory(size: Long): Unit = lock.synchronized {
if (size > _memoryUsed) {
logWarning(s"Attempted to release $size bytes of storage " +
s"memory when we only have ${_memoryUsed} bytes")
_memoryUsed = 0
} else {
_memoryUsed -= size
}
}
// 释放所有内存
def releaseAllMemory(): Unit = lock.synchronized {
_memoryUsed = 0
}
// 缩小内存池大小
def freeSpaceToShrinkPool(spaceToFree: Long): Long = lock.synchronized {
val spaceFreedByReleasingUnusedMemory = math.min(spaceToFree, memoryFree)
val remainingSpaceToFree = spaceToFree - spaceFreedByReleasingUnusedMemory
if (remainingSpaceToFree > 0) {
val spaceFreedByEviction =
memoryStore.evictBlocksToFreeSpace(None, remainingSpaceToFree, memoryMode)
// When a block is released, BlockManager.dropFromMemory() calls releaseMemory(), so we do
// not need to decrement _memoryUsed here. However, we do need to decrement the pool size.
spaceFreedByReleasingUnusedMemory + spaceFreedByEviction
} else {
spaceFreedByReleasingUnusedMemory
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
# 3.2.2 ExecutionMemoryPool
源码如下:
点击查看
// lock 是用于保证线程安全的锁对象,实际上是 MemoryManager 的实例
// memoryMode 标识内存模式为堆内内存还是堆外内存
private[memory] class ExecutionMemoryPool(
lock: Object,
memoryMode: MemoryMode
) extends MemoryPool(lock) with Logging {
// 内存池名称
private[this] val poolName: String = memoryMode match {
case MemoryMode.ON_HEAP => "on-heap execution"
case MemoryMode.OFF_HEAP => "off-heap execution"
}
// 任务尝试 id 与所消费的内存大小之间的映射关系
@GuardedBy("lock")
private val memoryForTask = new mutable.HashMap[Long, Long]()
// 已经使用的内存大小,单位为字节。为所有任务尝试所消费的内存大小之和。即 memoryForTask 中所有 value 的和。
override def memoryUsed: Long = lock.synchronized {
memoryForTask.values.sum
}
// 返回指定任务尝试所使用的内存大小
def getMemoryUsageForTask(taskAttemptId: Long): Long = lock.synchronized {
memoryForTask.getOrElse(taskAttemptId, 0L)
}
// 为给定的 taskAttemptId 所表示的任务尝试申请最大 numBytes 的内存,如果申请成功,则返回实际申请到的内存大小,否则返回 0。
// 在某些情况下,此调用可能会阻塞,直到有足够的可用内存以确保每个 task 在强制执行之前有机会至少达到总内存池的 1 / 2N(其中 N 是 active task 的数量)。
// 如果 task 数量增加但较旧的 task 已经拥有大量内存,则可能会发生阻塞。
private[memory] def acquireMemory(
numBytes: Long,
taskAttemptId: Long,
maybeGrowPool: Long => Unit = (additionalSpaceNeeded: Long) => (),
computeMaxPoolSize: () => Long = () => poolSize): Long = lock.synchronized {
assert(numBytes > 0, s"invalid number of bytes requested: $numBytes")
// 将此任务添加到任务内存映射中,以便可以准确计数
if (!memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) = 0L
lock.notifyAll()
}
// 对于当前 N 个 active task,必须保证在每个 task 溢出之前至少获得 1 / 2N,最多 1 / N 的内存。
// 由于 N 是动态变化的,所以要持续跟踪 active task 的状态,随时重新分配内存,所以使用 while 循环。
while (true) {
// 获取当前 active task 的数量
val numActiveTasks = memoryForTask.keys.size
// 获取当前任务尝试所消费的内存
val curMem = memoryForTask(taskAttemptId)
// 从 StorageMemoryPool 回收或者借用内存
maybeGrowPool(numBytes - memoryFree)
// 计算内存池最大大小
val maxPoolSize = computeMaxPoolSize()
// 计算每个任务尝试可以获得的最大内存大小
val maxMemoryPerTask = maxPoolSize / numActiveTasks
// 计算可以保证每个任务尝试运行的最小运行内存
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
// 我们可以为该任务尝试分配多少内存,将其大小保持在 0 <= X <= 1 / numActiveTasks。
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
// 计算当前任务尝试真正可以申请获取的内存
val toGrant = math.min(maxToGrant, memoryFree)
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free")
// 内存不足,开始等待
lock.wait()
} else {
// 获取内存成功
memoryForTask(taskAttemptId) += toGrant
return toGrant
}
}
0L // Never reached
}
// 为指定的任务尝试释放指定大小的内存
def releaseMemory(numBytes: Long, taskAttemptId: Long): Unit = lock.synchronized {
// 获取任务尝试所消费的内存
val curMem = memoryForTask.getOrElse(taskAttemptId, 0L)
// 计算能够释放的内存大小
val memoryToFree = if (curMem < numBytes) {
logWarning(
s"Internal error: release called on $numBytes bytes but task only has $curMem bytes " +
s"of memory from the $poolName pool")
curMem
} else {
numBytes
}
// 释放内存
if (memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) -= memoryToFree
if (memoryForTask(taskAttemptId) <= 0) {
memoryForTask.remove(taskAttemptId)
}
}
// 唤醒所有处于等待状态且需要申请内存的线程
lock.notifyAll()
}
// 释放指定任务尝试所消费的所有内存
def releaseAllMemoryForTask(taskAttemptId: Long): Long = lock.synchronized {
val numBytesToFree = getMemoryUsageForTask(taskAttemptId)
releaseMemory(numBytesToFree, taskAttemptId)
numBytesToFree
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
# 3.3 内存管理器
MemoryManager 是一个抽象的内存管理器,用来调配存储内存和执行内存之间内存使用问题,每个 JVM 中都有一个 MemoryManager
。MemoryManager 有两个实现类:StaticMemoryManager和UnifiedMemoryManager,分别代表静态内存管理和统一内存管理。
- 静态内存管理:实现类为
StaticMemoryManager,是 Spark 中最早的内存管理模式。表示在 Storage Memory 和 Execution Memory 之间存在静态边界,二者不可互相借用内存。两个区域的内存大小可以使用spark.storage.memoryFraction和spark.shuffle.memoryFraction参数指定。此模式下不存在堆外内存模型。从 Spark3.0 开始已经废弃。 - 统一内存管理:实现类为
UnifiedMemoryManager,从 Spark 1.6 开始引入,同时也引入了堆外内存的概念(详见SPARK-11389),且作为默认的内存管理器。表示在 Storage Memory 和 Execution Memory 之间存在软边界,二者可以互相借用内存使用。
MemoryManager 源码太多,而且其本身只是一个抽象类,核心逻辑是在其实现类中实现的,所以这里只看下其整体结构:
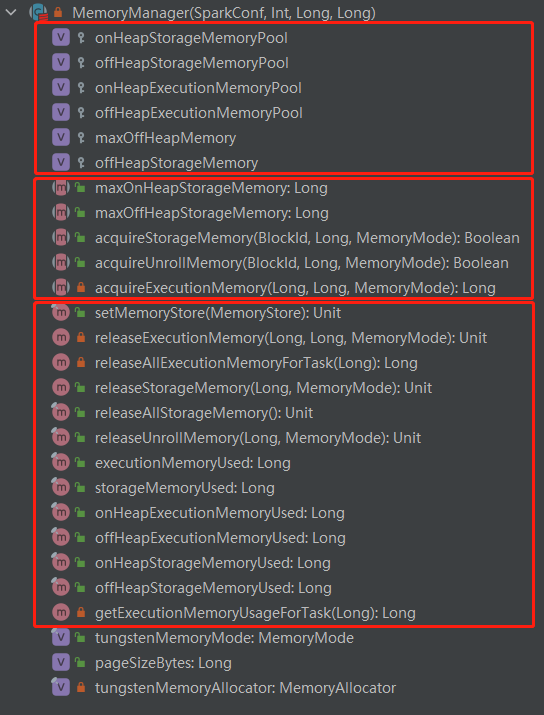
MemoryManager 的核心代码可以分三部分看:
- 第一部分是六个变量,其中四个是前面提到过的关于内存池的定义,另外两个定义堆外最大内存和堆外存储内存。
// 堆内存储内存
protected val onHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.ON_HEAP)
// 堆外存储内存
protected val offHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.OFF_HEAP)
// 堆内执行内存
protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.ON_HEAP)
// 堆外执行内存
protected val offHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.OFF_HEAP)
// 最大堆外内存
protected[this] val maxOffHeapMemory = conf.get(MEMORY_OFFHEAP_SIZE)
// 堆外存储内存
protected[this] val offHeapStorageMemory = (maxOffHeapMemory * conf.get(MEMORY_STORAGE_FRACTION)).toLong
2
3
4
5
6
7
8
9
10
11
12
13
- 第二部分是五个抽象方法,需要子类去实现。
// 最大堆内存储内存
def maxOnHeapStorageMemory: Long
// 最大堆外存储内存
def maxOffHeapStorageMemory: Long
// 为 blockId 表示的 Block 申请 numBytes 字节大小的堆外或者堆内内存
def acquireStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
// 获取 numBytes 字节的内存来展开 blockId 指定的 Block,必要时移除现有的 Block
def acquireUnrollMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
// 为 taskAttemptId 表示的任务尝试申请 numBytes 字节的内存
private[memory] def acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long
2
3
4
5
6
7
8
9
10
11
12
13
14
- 第三部分是一些有实现的方法。
点击查看
// 为 onHeapStorageMemoryPool 和 offHeapStorageMemoryPool 设置 MemoryStore
final def setMemoryStore(store: MemoryStore): Unit = synchronized {
onHeapStorageMemoryPool.setMemoryStore(store)
offHeapStorageMemoryPool.setMemoryStore(store)
}
// 为 taskAttemptId 表示的任务尝试释放 numBytes 字节的执行内存
private[memory] def releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Unit = synchronized {
memoryMode match {
case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.releaseMemory(numBytes, taskAttemptId)
case MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.releaseMemory(numBytes, taskAttemptId)
}
}
// 释放 taskAttemptId 表示的任务尝试占用的所有内存
private[memory] def releaseAllExecutionMemoryForTask(taskAttemptId: Long): Long = synchronized {
onHeapExecutionMemoryPool.releaseAllMemoryForTask(taskAttemptId) +
offHeapExecutionMemoryPool.releaseAllMemoryForTask(taskAttemptId)
}
// 释放 numBytes 字节的堆内或者堆外内存
def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unit = synchronized {
memoryMode match {
case MemoryMode.ON_HEAP => onHeapStorageMemoryPool.releaseMemory(numBytes)
case MemoryMode.OFF_HEAP => offHeapStorageMemoryPool.releaseMemory(numBytes)
}
}
// 释放堆内和堆外所有内存
final def releaseAllStorageMemory(): Unit = synchronized {
onHeapStorageMemoryPool.releaseAllMemory()
offHeapStorageMemoryPool.releaseAllMemory()
}
// 释放 numBytes 字节的展开内存
final def releaseUnrollMemory(numBytes: Long, memoryMode: MemoryMode): Unit = synchronized {
releaseStorageMemory(numBytes, memoryMode)
}
// 返回使用的执行内存大小,包括堆内内存和堆外内存
final def executionMemoryUsed: Long = synchronized {
onHeapExecutionMemoryPool.memoryUsed + offHeapExecutionMemoryPool.memoryUsed
}
// 返回使用的存储内存大小,包括堆内内存和堆外内存
final def storageMemoryUsed: Long = synchronized {
onHeapStorageMemoryPool.memoryUsed + offHeapStorageMemoryPool.memoryUsed
}
// 返回使用的堆内执行内存大小
final def onHeapExecutionMemoryUsed: Long = synchronized {
onHeapExecutionMemoryPool.memoryUsed
}
// 返回使用的堆外执行内存大小
final def offHeapExecutionMemoryUsed: Long = synchronized {
offHeapExecutionMemoryPool.memoryUsed
}
// 返回使用的堆内存储内存大小
final def onHeapStorageMemoryUsed: Long = synchronized {
onHeapStorageMemoryPool.memoryUsed
}
// 返回使用的堆外存储内存大小
final def offHeapStorageMemoryUsed: Long = synchronized {
offHeapStorageMemoryPool.memoryUsed
}
// 返回 taskAttemptId 表示的任务尝试使用的执行内存
private[memory] def getExecutionMemoryUsageForTask(taskAttemptId: Long): Long = synchronized {
onHeapExecutionMemoryPool.getMemoryUsageForTask(taskAttemptId) +
offHeapExecutionMemoryPool.getMemoryUsageForTask(taskAttemptId)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# 3.3.1 静态内存管理器
静态内存管理器的实现类为StaticMemoryManager,是 Spark 中最早的内存管理模式。表示在 Storage Memory 和 Execution Memory
之间存在静态边界,二者不可互相借用内存。两个区域的内存大小可以使用spark.storage.memoryFraction
和spark.shuffle.memoryFraction参数指定。此模式下不存在堆外内存模型。从 Spark3.0 开始已经废弃。
# 3.3.1.1 堆内内存
静态内存管理中堆内内存示意图如下:
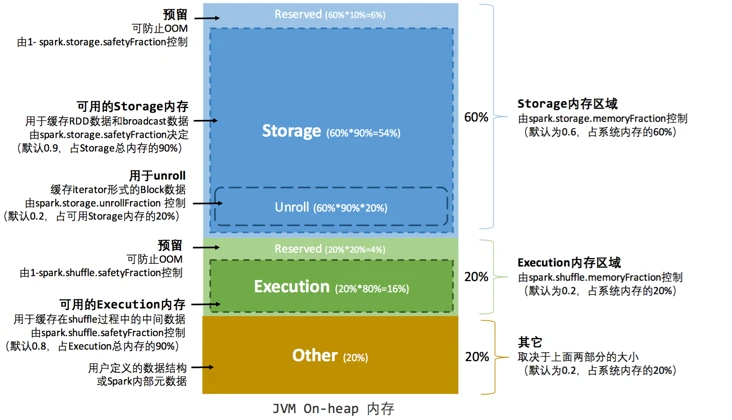
- 堆内存被整体划分为三部分:Storage Memory、Execution Memory 和 Other 部分。其中 Storage Memory 默认占用系统内存的
60%(由
spark.storage.memoryFraction参数指定),Execution Memory 默认占用系统内存的 20%(由spark.shuffle.memoryFraction参数指定),剩余部分为 Other(1 -spark.storage.memoryFraction-spark.shuffle.memoryFraction)。 - Storage Memory 中真正可用于存储的部分只占了整体 Storage Memory 的 90%(由
spark.storage.safetyFraction参数指定),剩余的 10%为保留内存,用于防止 OOM。相关源码如下:
private def getMaxStorageMemory(conf: SparkConf): Long = {
// 获取系统内存大小
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
// Storage Memory 默认占用系统内存 60%
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
// 存储内存真正可用的部分
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
2
3
4
5
6
7
8
9
- Execution Memory 中真正可用于执行计算的部分只占了整体 Execution Memory 的 80%(由
spark.shuffle.safetyFraction参数指定),剩余的 20%为保留内存,用于防止 OOM。
private def getMaxExecutionMemory(conf: SparkConf): Long = {
// 获取堆内存大小
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
if (systemMaxMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"System memory $systemMaxMemory must " +
s"be at least $MIN_MEMORY_BYTES. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$MIN_MEMORY_BYTES. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}
// Execution Memory 默认占堆内存的 20%
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
// 执行内存真正可用的部分
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- Other 部分用于存储用于定义的数据结构或 Spark 中元数据。
# 3.3.1.2 StaticMemoryManager 源码
点击查看
private[spark] class StaticMemoryManager(
conf: SparkConf,
maxOnHeapExecutionMemory: Long,
override val maxOnHeapStorageMemory: Long,
numCores: Int)
extends MemoryManager(
conf,
numCores,
maxOnHeapStorageMemory,
maxOnHeapExecutionMemory) {
def this(conf: SparkConf, numCores: Int) {
this(
conf,
StaticMemoryManager.getMaxExecutionMemory(conf),
StaticMemoryManager.getMaxStorageMemory(conf),
numCores)
}
offHeapExecutionMemoryPool.incrementPoolSize(offHeapStorageMemoryPool.poolSize)
offHeapStorageMemoryPool.decrementPoolSize(offHeapStorageMemoryPool.poolSize)
private val maxUnrollMemory: Long = {
(maxOnHeapStorageMemory * conf.getDouble("spark.storage.unrollFraction", 0.2)).toLong
}
override def maxOffHeapStorageMemory: Long = 0L
override def acquireStorageMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
require(memoryMode != MemoryMode.OFF_HEAP,
"StaticMemoryManager does not support off-heap storage memory")
if (numBytes > maxOnHeapStorageMemory) {
// Fail fast if the block simply won't fit
logInfo(s"Will not store $blockId as the required space ($numBytes bytes) exceeds our " +
s"memory limit ($maxOnHeapStorageMemory bytes)")
false
} else {
onHeapStorageMemoryPool.acquireMemory(blockId, numBytes)
}
}
override def acquireUnrollMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
require(memoryMode != MemoryMode.OFF_HEAP,
"StaticMemoryManager does not support off-heap unroll memory")
val currentUnrollMemory = onHeapStorageMemoryPool.memoryStore.currentUnrollMemory
val freeMemory = onHeapStorageMemoryPool.memoryFree
// When unrolling, we will use all of the existing free memory, and, if necessary,
// some extra space freed from evicting cached blocks. We must place a cap on the
// amount of memory to be evicted by unrolling, however, otherwise unrolling one
// big block can blow away the entire cache.
val maxNumBytesToFree = math.max(0, maxUnrollMemory - currentUnrollMemory - freeMemory)
// Keep it within the range 0 <= X <= maxNumBytesToFree
val numBytesToFree = math.max(0, math.min(maxNumBytesToFree, numBytes - freeMemory))
onHeapStorageMemoryPool.acquireMemory(blockId, numBytes, numBytesToFree)
}
private[memory]
override def acquireExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long = synchronized {
memoryMode match {
case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.acquireMemory(numBytes, taskAttemptId)
case MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.acquireMemory(numBytes, taskAttemptId)
}
}
}
private[spark] object StaticMemoryManager {
private val MIN_MEMORY_BYTES = 32 * 1024 * 1024
private def getMaxStorageMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
// Storage Memory 默认占用堆内存 60%
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
// 安全占比
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
private def getMaxExecutionMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
if (systemMaxMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"System memory $systemMaxMemory must " +
s"be at least $MIN_MEMORY_BYTES. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
// spark.executor.memory 至少需要32M
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$MIN_MEMORY_BYTES. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
# 3.3.2 统一内存管理器
统一内存管理器的实现类为UnifiedMemoryManager,从 Spark 1.6
开始引入,同时也引入了堆外内存的概念(详见SPARK-11389),且作为默认的内存管理器。表示在
Storage Memory 和 Execution Memory 之间存在软边界,二者可以互相借用内存使用。
# 3.3.2.1 堆内内存
统一内存中堆内内存示意图如下:
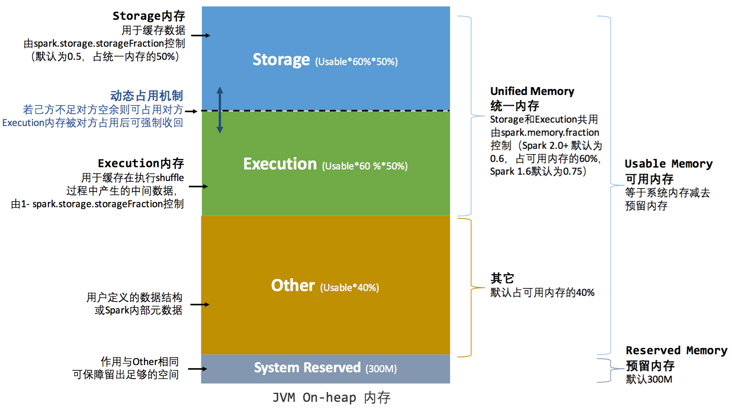
- 堆内存中首先为非存储、非执行目的预留固定数量 300M 的内存。源码中的定义如下:
private val RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024
- 统一管理的内存(即 Storage Memory 和 Execution Memory 共享的部分)占用了堆内存中减去保留的 300M 之外的
60%(由
spark.memory.fraction参数控制)。相关源码如下:
private def getMaxMemory(conf: SparkConf): Long = {
// 获取堆内内存
val systemMemory = conf.get(TEST_MEMORY)
// 保留内存,默认为 300M
val reservedMemory = conf.getLong(TEST_RESERVED_MEMORY.key,
if (conf.contains(IS_TESTING)) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +
s"option or ${config.DRIVER_MEMORY.key} in Spark configuration.")
}
// SPARK-12759 Check executor memory to fail fast if memory is insufficient
if (conf.contains(config.EXECUTOR_MEMORY)) {
val executorMemory = conf.getSizeAsBytes(config.EXECUTOR_MEMORY.key)
if (executorMemory < minSystemMemory) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$minSystemMemory. Please increase executor memory using the " +
s"--executor-memory option or ${config.EXECUTOR_MEMORY.key} in Spark configuration.")
}
}
// 可用内存 = 获取堆内内存 - 保留内存
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.get(config.MEMORY_FRACTION)
(usableMemory * memoryFraction).toLong
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- Storage Memory 和 Execution Memory 各占统一管理内存的 50%(由
spark.memory.storageFraction参数控制)。如果有一个 1GB 的 JVM,那么用于执行和存储的内存将默认为(1024 - 300) * 0.6 = 434MB。Storage Memory 和 Execution Memory 的初始化源码如下:
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
val maxMemory = getMaxMemory(conf)
new UnifiedMemoryManager(
conf,
maxHeapMemory = maxMemory,
// MEMORY_STORAGE_FRACTION 默认 0.5
onHeapStorageRegionSize = (maxMemory * conf.get(config.MEMORY_STORAGE_FRACTION)).toLong,
numCores = numCores)
}
2
3
4
5
6
7
8
9
# 3.3.2.2 堆外内存
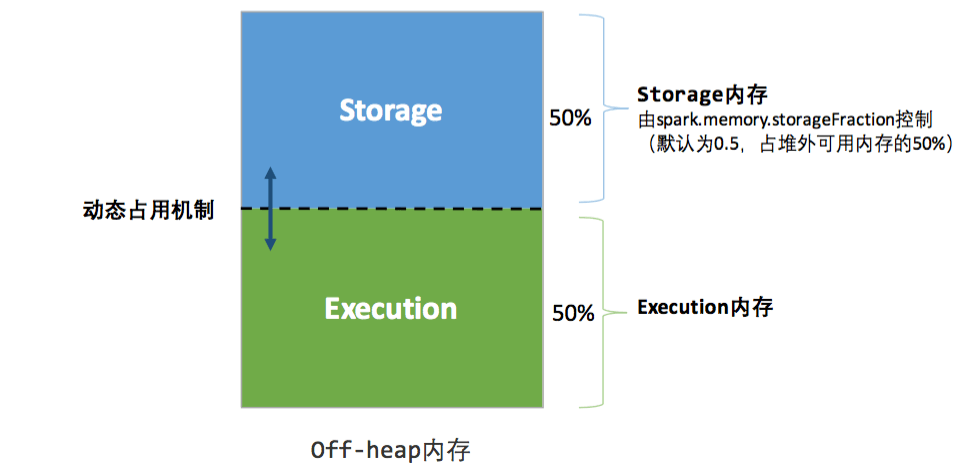
统一内存管理中堆外内存示意图如下:
- 堆外内存的使用由参数
spark.memory.offHeap.enabled控制,默认是不开启的。相关源码如下:
private[spark] val MEMORY_OFFHEAP_ENABLED = ConfigBuilder("spark.memory.offHeap.enabled")
.doc("If true, Spark will attempt to use off-heap memory for certain operations. " +
"If off-heap memory use is enabled, then spark.memory.offHeap.size must be positive.")
.version("1.6.0")
.withAlternative("spark.unsafe.offHeap")
.booleanConf
.createWithDefault(false)
2
3
4
5
6
7
- 堆外内存大小是由参数
spark.memory.offHeap.size控制的,默认为 0,也就是说如果要使用堆外内存,必须同时设置spark.memory.offHeap.enabled和spark.memory.offHeap.size。 - 堆外内存中的内存分布比较简单,只有 Storage Memory 和 Execution Memory,默认各占 50%,由
spark.memory.storageFraction控制。
# 3.3.2.3 内存借用关系
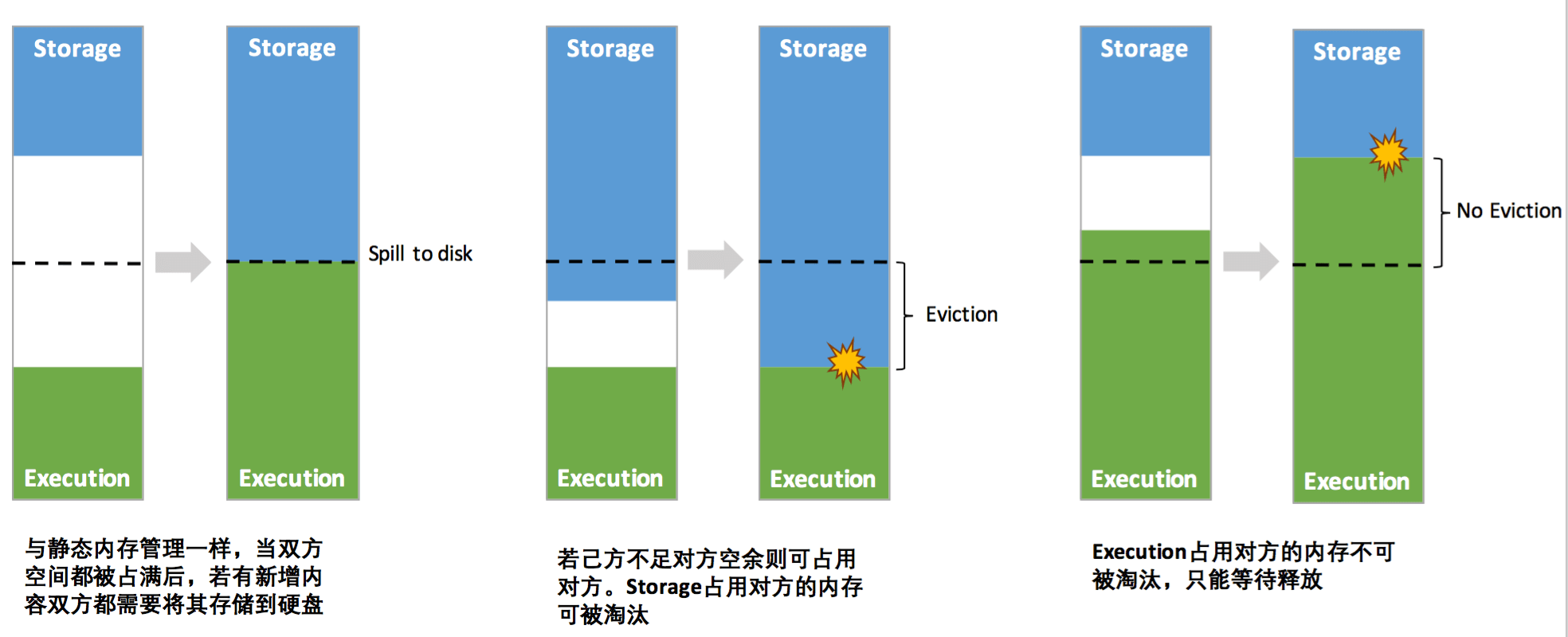
Storage Memory 和 Execution Memory 之间的借用逻辑是:
- 二者默认各占共享内存的 50%,共享内存大小为
(堆内存 - 300M) * 0.6。 - 当 Storage Memory 不够用时,会尽可能地借用 Execution Memory,如果 Execution Memory 需要回收空间时,Storage Memory 中缓存的 Block 会被移除,直到释放足够多的借用空间来满足 Execution Memory 的需求。
- 当 Execution Memory 内存不够用时,会尽可能多地借用 Storage Memory 内存,但是当 Storage Memory 内存不够用时,Execution Memory 不会为它释放借用的空间。主要原因是由于技术实现过于复杂。
内存动态机制是如何实现的?
说了这么多,那么 Storage Memory 和 Execution Memory 内存共享的动态机制在源码中是如何实现的呢?UnifiedMemoryManager
是MemoryManager的实现类,内存借用的动态性是体现在acquireStorageMemory和acquireExecutionMemory
两个方法中的。前者表示申请用于存储的内存,后者表示申请用于执行的内存。
先看 acquireStorageMemory的实现:
override def acquireStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean = synchronized {
assertInvariants()
assert(numBytes >= 0)
// 根据参数初始化执行内存池 executionPool、存储内存池 storagePool 和 最大可用内存 maxMemory
// 从源码来看,这里既包含了对堆内内存的处理,也包含了对堆外内存的处理
val (executionPool, storagePool, maxMemory) = memoryMode match {
case MemoryMode.ON_HEAP => (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
maxOnHeapStorageMemory)
case MemoryMode.OFF_HEAP => (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
maxOffHeapStorageMemory)
}
// 如果申请的内存大小 > 最大内存,直接退出
if (numBytes > maxMemory) {
logInfo(s"Will not store $blockId as the required space ($numBytes bytes) exceeds our " +
s"memory limit ($maxMemory bytes)")
return false
}
// 如果申请的内存大小 > 存储内存池当前可用内存大小,说明存储内存池空间不足,到计算内存池中借用
if (numBytes > storagePool.memoryFree) {
val memoryBorrowedFromExecution = Math.min(executionPool.memoryFree,
numBytes - storagePool.memoryFree)
executionPool.decrementPoolSize(memoryBorrowedFromExecution)
storagePool.incrementPoolSize(memoryBorrowedFromExecution)
}
storagePool.acquireMemory(blockId, numBytes)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
acquireExecutionMemory 的实现:
override private[memory] def acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long = synchronized {
assertInvariants()
assert(numBytes >= 0)
// 根据参数初始化执行内存池 executionPool、存储内存池 storagePool 和 最大可用内存 maxMemory
val (executionPool, storagePool, storageRegionSize, maxMemory) = memoryMode match {
case MemoryMode.ON_HEAP => (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
onHeapStorageRegionSize,
maxHeapMemory)
case MemoryMode.OFF_HEAP => (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
offHeapStorageMemory,
maxOffHeapMemory)
}
// 通过清除缓存块来扩大执行池,从而缩小存储池。必要时会清除已经缓存的 Block。
def maybeGrowExecutionPool(extraMemoryNeeded: Long): Unit = {
if (extraMemoryNeeded > 0) {
val memoryReclaimableFromStorage = math.max(
storagePool.memoryFree,
storagePool.poolSize - storageRegionSize)
if (memoryReclaimableFromStorage > 0) {
// Only reclaim as much space as is necessary and available:
val spaceToReclaim = storagePool.freeSpaceToShrinkPool(
math.min(extraMemoryNeeded, memoryReclaimableFromStorage))
storagePool.decrementPoolSize(spaceToReclaim)
executionPool.incrementPoolSize(spaceToReclaim)
}
}
}
// 计算清除过缓存内存之后的执行内存大小
def computeMaxExecutionPoolSize(): Long = {
maxMemory - math.min(storagePool.memoryUsed, storageRegionSize)
}
executionPool.acquireMemory(
numBytes, taskAttemptId, maybeGrowExecutionPool, () => computeMaxExecutionPoolSize)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 3.3.2.4 UnifiedMemoryManager 源码
点击查看
private[spark] class UnifiedMemoryManager(
conf: SparkConf,
val maxHeapMemory: Long,
onHeapStorageRegionSize: Long,
numCores: Int)
extends MemoryManager(
conf,
numCores,
onHeapStorageRegionSize,
maxHeapMemory - onHeapStorageRegionSize) {
private def assertInvariants(): Unit = {
assert(onHeapExecutionMemoryPool.poolSize + onHeapStorageMemoryPool.poolSize == maxHeapMemory)
assert(
offHeapExecutionMemoryPool.poolSize + offHeapStorageMemoryPool.poolSize == maxOffHeapMemory)
}
assertInvariants()
override def maxOnHeapStorageMemory: Long = synchronized {
maxHeapMemory - onHeapExecutionMemoryPool.memoryUsed
}
override def maxOffHeapStorageMemory: Long = synchronized {
maxOffHeapMemory - offHeapExecutionMemoryPool.memoryUsed
}
override private[memory] def acquireExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long = synchronized {
assertInvariants()
assert(numBytes >= 0)
val (executionPool, storagePool, storageRegionSize, maxMemory) = memoryMode match {
case MemoryMode.ON_HEAP => (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
onHeapStorageRegionSize,
maxHeapMemory)
case MemoryMode.OFF_HEAP => (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
offHeapStorageMemory,
maxOffHeapMemory)
}
def maybeGrowExecutionPool(extraMemoryNeeded: Long): Unit = {
if (extraMemoryNeeded > 0) {
// There is not enough free memory in the execution pool, so try to reclaim memory from
// storage. We can reclaim any free memory from the storage pool. If the storage pool
// has grown to become larger than `storageRegionSize`, we can evict blocks and reclaim
// the memory that storage has borrowed from execution.
val memoryReclaimableFromStorage = math.max(
storagePool.memoryFree,
storagePool.poolSize - storageRegionSize)
if (memoryReclaimableFromStorage > 0) {
// Only reclaim as much space as is necessary and available:
val spaceToReclaim = storagePool.freeSpaceToShrinkPool(
math.min(extraMemoryNeeded, memoryReclaimableFromStorage))
storagePool.decrementPoolSize(spaceToReclaim)
executionPool.incrementPoolSize(spaceToReclaim)
}
}
}
def computeMaxExecutionPoolSize(): Long = {
maxMemory - math.min(storagePool.memoryUsed, storageRegionSize)
}
executionPool.acquireMemory(
numBytes, taskAttemptId, maybeGrowExecutionPool, () => computeMaxExecutionPoolSize)
}
override def acquireStorageMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
assertInvariants()
assert(numBytes >= 0)
val (executionPool, storagePool, maxMemory) = memoryMode match {
case MemoryMode.ON_HEAP => (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
maxOnHeapStorageMemory)
case MemoryMode.OFF_HEAP => (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
maxOffHeapStorageMemory)
}
if (numBytes > maxMemory) {
// Fail fast if the block simply won't fit
logInfo(s"Will not store $blockId as the required space ($numBytes bytes) exceeds our " +
s"memory limit ($maxMemory bytes)")
return false
}
if (numBytes > storagePool.memoryFree) {
// There is not enough free memory in the storage pool, so try to borrow free memory from
// the execution pool.
val memoryBorrowedFromExecution = Math.min(executionPool.memoryFree,
numBytes - storagePool.memoryFree)
executionPool.decrementPoolSize(memoryBorrowedFromExecution)
storagePool.incrementPoolSize(memoryBorrowedFromExecution)
}
storagePool.acquireMemory(blockId, numBytes)
}
override def acquireUnrollMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = synchronized {
acquireStorageMemory(blockId, numBytes, memoryMode)
}
}
object UnifiedMemoryManager {
private val RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
val maxMemory = getMaxMemory(conf)
new UnifiedMemoryManager(
conf,
maxHeapMemory = maxMemory,
onHeapStorageRegionSize = (maxMemory * conf.get(config.MEMORY_STORAGE_FRACTION)).toLong,
numCores = numCores)
}
private def getMaxMemory(conf: SparkConf): Long = {
val systemMemory = conf.get(TEST_MEMORY)
val reservedMemory = conf.getLong(TEST_RESERVED_MEMORY.key,
if (conf.contains(IS_TESTING)) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +
s"option or ${config.DRIVER_MEMORY.key} in Spark configuration.")
}
// SPARK-12759 Check executor memory to fail fast if memory is insufficient
if (conf.contains(config.EXECUTOR_MEMORY)) {
val executorMemory = conf.getSizeAsBytes(config.EXECUTOR_MEMORY.key)
if (executorMemory < minSystemMemory) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$minSystemMemory. Please increase executor memory using the " +
s"--executor-memory option or ${config.EXECUTOR_MEMORY.key} in Spark configuration.")
}
}
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.get(config.MEMORY_FRACTION)
(usableMemory * memoryFraction).toLong
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
# 3.4 内存存储
前面一直在说 Spark 中的存储体系架构以及内存是如何规划和使用的,但是并没有说 Block 在内存中是如何存储的,是直接存对象?还是序列化之后存?是用数组存?还是用 Hash 存?
Spark 中负责 Block 在内存中存储的组件是MemoryStore,而 Block 在内存中的存储对象被抽象为MemoryEntry。
# 3.4.1 MemoryEntry
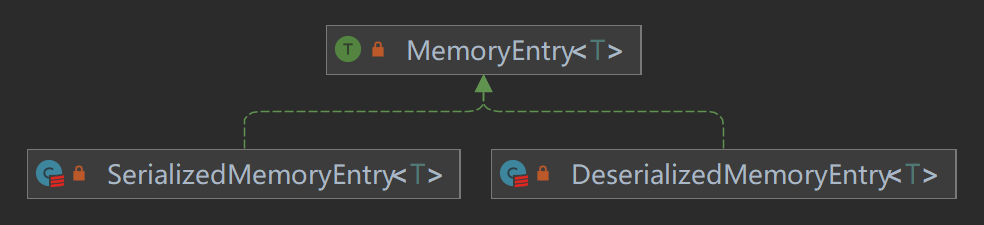
MemoryEntry是一个特质,它有两个实现类是SerializedMemoryEntry和DeserializedMemoryEntry,分别表示序列化后的
MemoryEntry 和反序列化后的 MemoryEntry,
源码如下:
private sealed trait MemoryEntry[T] {
// 当前 Block 大小
def size: Long
// 内存模式,ON_HEAP 或 OFF_HEAP
def memoryMode: MemoryMode
// Block 的类型标记
def classTag: ClassTag[T]
}
private case class DeserializedMemoryEntry[T](
value: Array[T],
size: Long,
classTag: ClassTag[T]) extends MemoryEntry[T] {
val memoryMode: MemoryMode = MemoryMode.ON_HEAP
}
private case class SerializedMemoryEntry[T](
buffer: ChunkedByteBuffer,
memoryMode: MemoryMode,
classTag: ClassTag[T]) extends MemoryEntry[T] {
def size: Long = buffer.size
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 3.4.2 MemoryStore
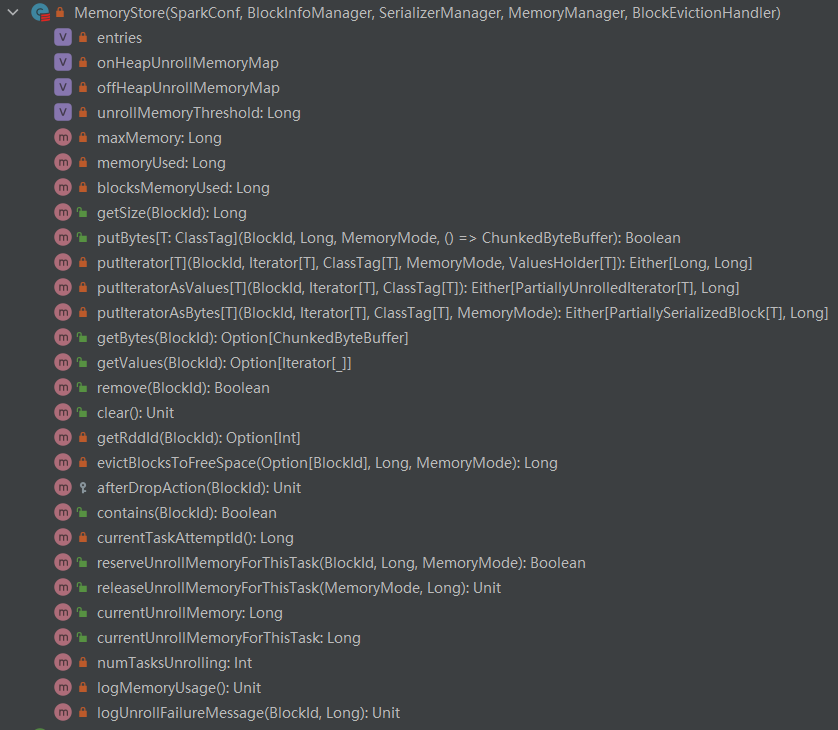
MemoryStore 的类结构如图所示,其中putBytes、putIterator、putIteratorAsValues和putIteratorAsBytes是将给定类型的
Block 存储到内存中,而getBytes和getValues是从内存中读取 Block 的值,evictBlocksToFreeSpace则是将某个特定的 Block
从内存中移除以释放空间。
MemoryStore 的内容比较多,这里挑几个分析下。
- blockEvictionHandler:MemoryStore 构造参数中的 BlockEvictionHandler 类型型参数 blockEvictionHandler,实际上就是 BlockManager。因为 BlockEvictionHandler 有且只有 BlockManager 一个实现类。BlockEvictionHandler 提供了从内存中移除 Block 的能力。
private[storage] trait BlockEvictionHandler {
private[storage] def dropFromMemory[T: ClassTag](
blockId: BlockId,
data: () => Either[Array[T], ChunkedByteBuffer]): StorageLevel
}
2
3
4
5
- entries:entries 是真正在内存里存储 Block 的对象,维护了 BlockId 和 MemoryEntry 的映射关系。
private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
- putBytes:将封装为 ChunkedByteBuffer 类型的 Block 写入内存。
def putBytes[T: ClassTag](blockId: BlockId, size: Long, memoryMode: MemoryMode, _bytes: () => ChunkedByteBuffer): Boolean = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
// 申请 size 大小的内存,如果申请成功则继续写入,否则直接返回false
if (memoryManager.acquireStorageMemory(blockId, size, memoryMode)) {
val bytes = _bytes()
assert(bytes.size == size)
// 将 ChunkedByteBuffer 进一步封装为 SerializedMemoryEntry
val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]])
// 加锁并保存到 entries 中
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as bytes in memory (estimated size %s, free %s)".format(
blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
true
} else {
false
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- putIterator:以迭代器的形式将 Block 写入内存中。由于有些 Block 是大对象,直接将其放入内存很容易引发 OOM,为了避免这种情况所以将其转为迭代器渐进式地展开并写入内存,且在展开过程中会周期性地检查是否有足够的内存用于写入。
private def putIterator[T](blockId: BlockId, values: Iterator[T], classTag: ClassTag[T], memoryMode: MemoryMode, valuesHolder: ValuesHolder[T]): Either[Long, Long] = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
// 已经展开的元素数量
var elementsUnrolled = 0
// 是否有足够的内存支持我们继续展开迭代器
var keepUnrolling = true
// 用来展开迭代器之前初始请求的内存大小
val initialMemoryThreshold = unrollMemoryThreshold
// 展开过程中进行内存检查的周期,单位是次数,默认值为16,可以通过参数 spark.storage.unrollMemoryCheckPeriod 设置
val memoryCheckPeriod = conf.get(UNROLL_MEMORY_CHECK_PERIOD)
// 当前任务用于展开Block所保留的内存
var memoryThreshold = initialMemoryThreshold
// 展开内存不足时,请求增长的因子
val memoryGrowthFactor = conf.get(UNROLL_MEMORY_GROWTH_FACTOR)
// Block已经使用的展开内存大小
var unrollMemoryUsedByThisBlock = 0L
// 请求是否有足够的内存支持我们继续展开迭代器
keepUnrolling = reserveUnrollMemoryForThisTask(blockId, initialMemoryThreshold, memoryMode)
if (!keepUnrolling) {
logWarning(s"Failed to reserve initial memory threshold of " +
s"${Utils.bytesToString(initialMemoryThreshold)} for computing block $blockId in memory.")
} else {
// 如果支持,将已经使用的内存更新
unrollMemoryUsedByThisBlock += initialMemoryThreshold
}
// 只要有足够的展开内存,就不断迭代
while (values.hasNext && keepUnrolling) {
// 记录 value
valuesHolder.storeValue(values.next())
// 周期性地检查
if (elementsUnrolled % memoryCheckPeriod == 0) {
val currentSize = valuesHolder.estimatedSize()
// If our vector's size has exceeded the threshold, request more memory
if (currentSize >= memoryThreshold) {
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong
// 更新 keepUnrolling
keepUnrolling = reserveUnrollMemoryForThisTask(blockId, amountToRequest, memoryMode)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
memoryThreshold += amountToRequest
}
}
elementsUnrolled += 1
}
// 申请到了足够的展开内存,写入数据
if (keepUnrolling) {
val entryBuilder = valuesHolder.getBuilder()
val size = entryBuilder.preciseSize
if (size > unrollMemoryUsedByThisBlock) {
val amountToRequest = size - unrollMemoryUsedByThisBlock
keepUnrolling = reserveUnrollMemoryForThisTask(blockId, amountToRequest, memoryMode)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
}
if (keepUnrolling) {
val entry = entryBuilder.build()
memoryManager.synchronized {
releaseUnrollMemoryForThisTask(memoryMode, unrollMemoryUsedByThisBlock)
val success = memoryManager.acquireStorageMemory(blockId, entry.size, memoryMode)
assert(success, "transferring unroll memory to storage memory failed")
}
// 写入
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as values in memory (estimated size %s, free %s)".format(blockId,
Utils.bytesToString(entry.size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
Right(entry.size)
} else {
logUnrollFailureMessage(blockId, entryBuilder.preciseSize)
Left(unrollMemoryUsedByThisBlock)
}
} else {
logUnrollFailureMessage(blockId, valuesHolder.estimatedSize())
Left(unrollMemoryUsedByThisBlock)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
- getBytes:从内存中读取 SerializedMemoryEntry 表示的 Block。
def getBytes(blockId: BlockId): Option[ChunkedByteBuffer] = {
val entry = entries.synchronized {
entries.get(blockId)
}
entry match {
case null => None
case e: DeserializedMemoryEntry[_] =>
throw new IllegalArgumentException("should only call getBytes on serialized blocks")
case SerializedMemoryEntry(bytes, _, _) => Some(bytes)
}
}
2
3
4
5
6
7
8
9
10
11
- getValues:从内存中读取 DeserializedMemoryEntry 表示的 Block。
def getValues(blockId: BlockId): Option[Iterator[_]] = {
val entry = entries.synchronized {
entries.get(blockId)
}
entry match {
case null => None
case e: SerializedMemoryEntry[_] =>
throw new IllegalArgumentException("should only call getValues on deserialized blocks")
case DeserializedMemoryEntry(values, _, _) =>
val x = Some(values)
x.map(_.iterator)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 4. 磁盘管理
Spark 除了会将数据存储到内存,还会在磁盘中进行存储。比如当 StorageLevel 中的 useDisk 属性为 true 时,就会将对应的 Block 写到磁盘,或者在 Shuffle 过程中如果达到溢写条件,也会将中间数据写到磁盘中。
相对内存来说,Spark 对磁盘的管理明显要简单很多。和磁盘管理相关的有两个核心类:DiskBlockManager和DiskStore。
DiskBlockManager和MemoryManager的功能类似,规划磁盘的使用情况,就是维护 Block 和物理磁盘位置之间的逻辑映射。DiskStore则和MemoryStore功能类似,提供了 Block 在磁盘上被存储和读取的能力。
DiskBlockManager和DiskStore内容比较简单,直接上源码。
# 4.1 磁盘管理器
DiskBlockManager对磁盘的目录规划如下:
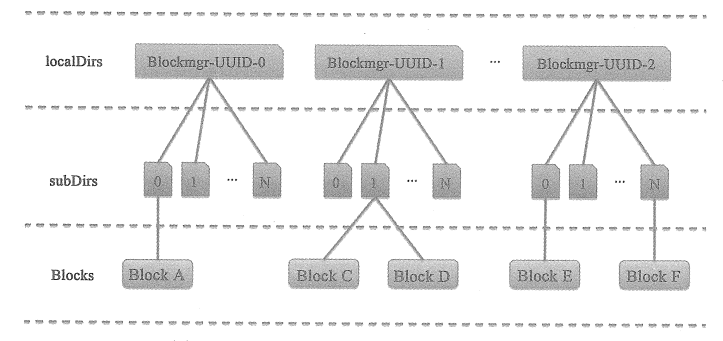
整体呈三级目录分布,一级目录由createLocalDirs方法创建,目录前缀为blockmgr-,后缀为UUID。每个一级目录下有 N 个二级目录,每个二级目录下又有若干个 Block 文件。
点击查看
private[spark] class DiskBlockManager(conf: SparkConf, deleteFilesOnStop: Boolean) extends Logging {
private[spark] val subDirsPerLocalDir = conf.get(config.DISKSTORE_SUB_DIRECTORIES)
private[spark] val localDirs: Array[File] = createLocalDirs(conf)
if (localDirs.isEmpty) {
logError("Failed to create any local dir.")
System.exit(ExecutorExitCode.DISK_STORE_FAILED_TO_CREATE_DIR)
}
private[spark] val localDirsString: Array[String] = localDirs.map(_.toString)
private val subDirs = Array.fill(localDirs.length)(new Array[File](subDirsPerLocalDir))
private val shutdownHook = addShutdownHook()
def getFile(filename: String): File = {
// Figure out which local directory it hashes to, and which subdirectory in that
val hash = Utils.nonNegativeHash(filename)
val dirId = hash % localDirs.length
val subDirId = (hash / localDirs.length) % subDirsPerLocalDir
val subDir = subDirs(dirId).synchronized {
val old = subDirs(dirId)(subDirId)
if (old != null) {
old
} else {
val newDir = new File(localDirs(dirId), "%02x".format(subDirId))
if (!newDir.exists() && !newDir.mkdir()) {
throw new IOException(s"Failed to create local dir in $newDir.")
}
subDirs(dirId)(subDirId) = newDir
newDir
}
}
new File(subDir, filename)
}
def getFile(blockId: BlockId): File = getFile(blockId.name)
def containsBlock(blockId: BlockId): Boolean = {
getFile(blockId.name).exists()
}
def getAllFiles(): Seq[File] = {
subDirs.flatMap { dir =>
dir.synchronized {
dir.clone()
}
}.filter(_ != null).flatMap { dir =>
val files = dir.listFiles()
if (files != null) files else Seq.empty
}
}
def getAllBlocks(): Seq[BlockId] = {
getAllFiles().flatMap { f =>
try {
Some(BlockId(f.getName))
} catch {
case _: UnrecognizedBlockId =>
None
}
}
}
def createTempLocalBlock(): (TempLocalBlockId, File) = {
var blockId = new TempLocalBlockId(UUID.randomUUID())
while (getFile(blockId).exists()) {
blockId = new TempLocalBlockId(UUID.randomUUID())
}
(blockId, getFile(blockId))
}
def createTempShuffleBlock(): (TempShuffleBlockId, File) = {
var blockId = new TempShuffleBlockId(UUID.randomUUID())
while (getFile(blockId).exists()) {
blockId = new TempShuffleBlockId(UUID.randomUUID())
}
(blockId, getFile(blockId))
}
private def createLocalDirs(conf: SparkConf): Array[File] = {
Utils.getConfiguredLocalDirs(conf).flatMap { rootDir =>
try {
val localDir = Utils.createDirectory(rootDir, "blockmgr")
logInfo(s"Created local directory at $localDir")
Some(localDir)
} catch {
case e: IOException =>
logError(s"Failed to create local dir in $rootDir. Ignoring this directory.", e)
None
}
}
}
private def addShutdownHook(): AnyRef = {
logDebug("Adding shutdown hook") // force eager creation of logger
ShutdownHookManager.addShutdownHook(ShutdownHookManager.TEMP_DIR_SHUTDOWN_PRIORITY + 1) { () =>
logInfo("Shutdown hook called")
DiskBlockManager.this.doStop()
}
}
private[spark] def stop(): Unit = {
try {
ShutdownHookManager.removeShutdownHook(shutdownHook)
} catch {
case e: Exception =>
logError(s"Exception while removing shutdown hook.", e)
}
doStop()
}
private def doStop(): Unit = {
if (deleteFilesOnStop) {
localDirs.foreach { localDir =>
if (localDir.isDirectory() && localDir.exists()) {
try {
if (!ShutdownHookManager.hasRootAsShutdownDeleteDir(localDir)) {
Utils.deleteRecursively(localDir)
}
} catch {
case e: Exception =>
logError(s"Exception while deleting local spark dir: $localDir", e)
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
# 4.2 磁盘存储
点击查看
private[spark] class DiskStore(
conf: SparkConf,
diskManager: DiskBlockManager,
securityManager: SecurityManager) extends Logging {
private val minMemoryMapBytes = conf.get(config.STORAGE_MEMORY_MAP_THRESHOLD)
private val maxMemoryMapBytes = conf.get(config.MEMORY_MAP_LIMIT_FOR_TESTS)
private val blockSizes = new ConcurrentHashMap[BlockId, Long]()
def getSize(blockId: BlockId): Long = blockSizes.get(blockId)
def put(blockId: BlockId)(writeFunc: WritableByteChannel => Unit): Unit = {
if (contains(blockId)) {
throw new IllegalStateException(s"Block $blockId is already present in the disk store")
}
logDebug(s"Attempting to put block $blockId")
val startTimeNs = System.nanoTime()
val file = diskManager.getFile(blockId)
val out = new CountingWritableChannel(openForWrite(file))
var threwException: Boolean = true
try {
writeFunc(out)
blockSizes.put(blockId, out.getCount)
threwException = false
} finally {
try {
out.close()
} catch {
case ioe: IOException =>
if (!threwException) {
threwException = true
throw ioe
}
} finally {
if (threwException) {
remove(blockId)
}
}
}
logDebug(s"Block ${file.getName} stored as ${Utils.bytesToString(file.length())} file" +
s" on disk in ${TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startTimeNs)} ms")
}
def putBytes(blockId: BlockId, bytes: ChunkedByteBuffer): Unit = {
put(blockId) { channel =>
bytes.writeFully(channel)
}
}
def getBytes(blockId: BlockId): BlockData = {
getBytes(diskManager.getFile(blockId.name), getSize(blockId))
}
def getBytes(f: File, blockSize: Long): BlockData = securityManager.getIOEncryptionKey() match {
case Some(key) =>
new EncryptedBlockData(f, blockSize, conf, key)
case _ =>
new DiskBlockData(minMemoryMapBytes, maxMemoryMapBytes, f, blockSize)
}
def remove(blockId: BlockId): Boolean = {
blockSizes.remove(blockId)
val file = diskManager.getFile(blockId.name)
if (file.exists()) {
val ret = file.delete()
if (!ret) {
logWarning(s"Error deleting ${file.getPath()}")
}
ret
} else {
false
}
}
def moveFileToBlock(sourceFile: File, blockSize: Long, targetBlockId: BlockId): Unit = {
blockSizes.put(targetBlockId, blockSize)
val targetFile = diskManager.getFile(targetBlockId.name)
FileUtils.moveFile(sourceFile, targetFile)
}
def contains(blockId: BlockId): Boolean = {
val file = diskManager.getFile(blockId.name)
file.exists()
}
private def openForWrite(file: File): WritableByteChannel = {
val out = new FileOutputStream(file).getChannel()
try {
securityManager.getIOEncryptionKey().map { key =>
CryptoStreamUtils.createWritableChannel(out, conf, key)
}.getOrElse(out)
} catch {
case e: Exception =>
Closeables.close(out, true)
file.delete()
throw e
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100