Spark DAGScheduler 源码分析
# 1. DAGScheduler 在调度中的位置
Spark 资源调度分为两层:
- 第一层是 Cluster Manager 将资源分配给 Application。其中 Cluster Manager 在 Standalone 模式下是 Master,在 Yarn 模式下是 ResourceManage,在 Mesos 模式下是 Mesos Master。
- 第二层是 Application 将资源分配给各个 Task。这一层的调度主要是由 DAGScheduler 和 TaskScheduler 完成。
DAGScheduler,顾名思义是 DAG 的调度器,但实际上调度的对象是 Stage,因为 DAG 是由一个个 Stage 所组成的一个抽象概念,在 Spark 源码中并没有关于 DAG 的抽象。
DAGScheduler 将 Stage 内部的 TaskSet 提交给 TaskScheduler,由 TaskScheduler 再对 Task 进行更低级别的调度。
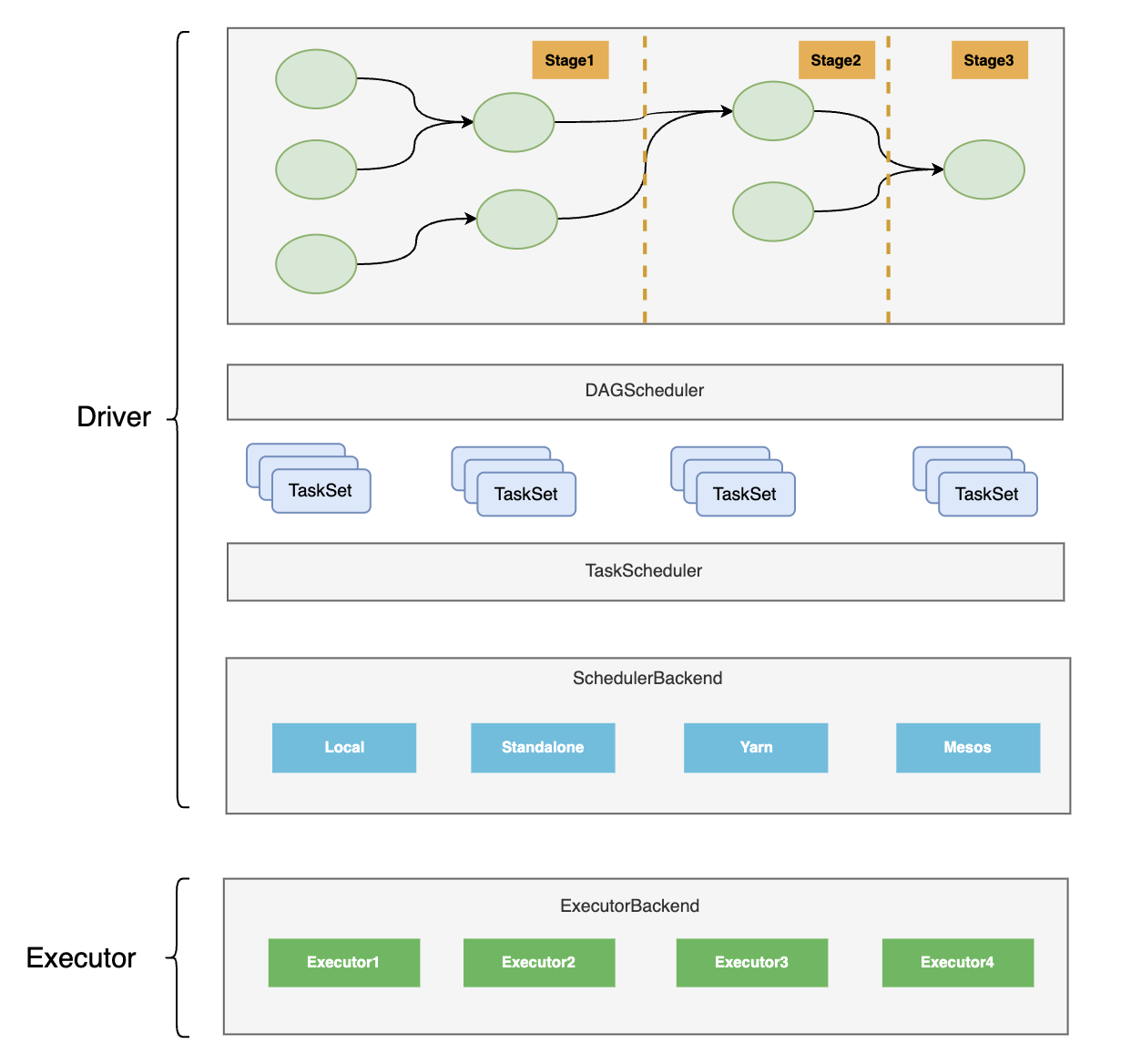
由于 DAGScheduler 和 TaskScheduler 内容较多,这篇内容主要描述 DAGScheduler,TaskScheduler 放在后续的文章中。
# 2. DAGScheduler 依赖
DAGScheduler 实现了 Stage 级的调度,它为每个 Job 计算 Stage 的 DAG,跟踪具体化的 RDD 和 Stage 输出,并为 Job 寻求一个代价最小的调度方案。然后,它将 Stage 以 TaskSet 的方式提交给底层的 TaskScheduler。TaskSet 包含完全独立的 Task,这些 Task 可以根据集群上已有的数据(例如之前 Stage map 输出文件)立即运行,但如果该数据不可用,TaskSet 可能会失败。
在开始了解 DAGScheduler 之前,需要先了解下面几个概念,因为 DAGScheduler 的实现离不开它们。
- ActiveJob:用于表示被 DAGScheduler 接受并处理的 Job。
- DAGSchedulerEvent:用于被 DAGScheduler 处理的事件抽象。
- DAGSchedulerEventProcessLoop:用于处理 DAGSchedulerEvent 的事件循环处理器。
- JobListener:Job 的监听器,定义了监听器的接口和规范。
# 2.1 ActiveJob
ActiveJob 表示 DAGScheduler 中正在运行的 Job。Job 可以有两种类型:Result Job(计算 ResultStage 并执行 action 算子)或 Map Stage Job(在提交任何下游 Stage 之前计算 ShuffleMapStage 的 map 输出)。后者用于自适应查询规划,在提交后续 Stage 之前查看 map 输出的统计信息。通过 finalStage 字段来区分这两种类型的 Job。
private[spark] class ActiveJob(
val jobId: Int, // Job 的身份标识
val finalStage: Stage, // Job 的最下游 Stage
val callSite: CallSite, // 应用程序调用栈
val listener: JobListener, // 监听当前 Job 的监听器
val properties: Properties) {
// 当前 Job 的分区数量
val numPartitions = finalStage match {
case r: ResultStage => r.partitions.length
case m: ShuffleMapStage => m.rdd.partitions.length
}
// 每个数组索引值表示一个分区的任务是否被执行完成
val finished = Array.fill[Boolean](numPartitions)(false)
// 当前 Job 中已经完成的任务数量
var numFinished = 0
def resetAllPartitions(): Unit = {
(0 until numPartitions).foreach(finished.update(_, false))
numFinished = 0
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 2.2 DAGSchedulerEvent
DAGSchedulerEvent 用于被 DAGScheduler 处理的事件抽象,和 RPC 通信的过程类似。
DAGSchedulerEvent 本身是一个没有任何实现的 trait,它的实现都是一些case class,这些case class代表了不同的事件,DAGScheduler 接受到该事件之后会将其提交给 DAGSchedulerEventProcessLoop,DAGSchedulerEventProcessLoop 接受到之后会通过模式匹配进行相应的处理。
private[scheduler] sealed trait DAGSchedulerEvent
private[scheduler] case class JobSubmitted(
jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties = null)
extends DAGSchedulerEvent
private[scheduler] case class MapStageSubmitted(
jobId: Int,
dependency: ShuffleDependency[_, _, _],
callSite: CallSite,
listener: JobListener,
properties: Properties = null)
extends DAGSchedulerEvent
private[scheduler] case class StageCancelled(
stageId: Int,
reason: Option[String])
extends DAGSchedulerEvent
private[scheduler] case class JobCancelled(
jobId: Int,
reason: Option[String])
extends DAGSchedulerEvent
private[scheduler] case class JobGroupCancelled(groupId: String) extends DAGSchedulerEvent
private[scheduler] case object AllJobsCancelled extends DAGSchedulerEvent
private[scheduler]] case class BeginEvent(task: Task[_], taskInfo: TaskInfo) extends DAGSchedulerEvent
private[scheduler] case class GettingResultEvent(taskInfo: TaskInfo) extends DAGSchedulerEvent
private[scheduler] case class CompletionEvent(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Seq[AccumulatorV2[_, _]],
metricPeaks: Array[Long],
taskInfo: TaskInfo)
extends DAGSchedulerEvent
private[scheduler] case class ExecutorAdded(execId: String, host: String) extends DAGSchedulerEvent
private[scheduler] case class ExecutorLost(execId: String, reason: ExecutorLossReason) extends DAGSchedulerEvent
private[scheduler] case class WorkerRemoved(workerId: String, host: String, message: String) extends DAGSchedulerEvent
private[scheduler] case class TaskSetFailed(taskSet: TaskSet, reason: String, exception: Option[Throwable]) extends DAGSchedulerEvent
private[scheduler] case object ResubmitFailedStages extends DAGSchedulerEvent
private[scheduler] case class SpeculativeTaskSubmitted(task: Task[_]) extends DAGSchedulerEvent
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 2.3 DAGSchedulerEventProcessLoop
DAGSchedulerEventProcessLoop 是 DAGScheduler 中非常重要的一个组件,但是它的实现相当简单。如果你看过我前面写的 RPC 通信那篇,那就很容易理解,DAGSchedulerEventProcessLoop 和 Dispatcher 中 MessageLoop 的实现高度相似。
提示
DAGSchedulerEventProcessLoop 的实现采用了设计模式中的模板方法模式,即在超类中定义了一个算法的框架,允许子类在不修改结构的前提下重写算法的特定步骤。Spark 中很多地方采用了此设计模式。
private[spark] abstract class EventLoop[E](name: String) extends Logging {
// 用于维护 DAGSchedulerEvent 的队列
// DAGScheduler 通过 调用 post 方法向其添加数据
// eventThread 的常驻线程中不断的轮询去消费
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
private val stopped = new AtomicBoolean(false)
private[spark] val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
// 通过轮询不断地消费事件
val event = eventQueue.take()
try {
// 拿到事件之后去处理
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
def start(): Unit = {
if (stopped.get) {
throw new IllegalStateException(name + " has already been stopped")
}
onStart()
eventThread.start()
}
def stop(): Unit = {
if (stopped.compareAndSet(false, true)) {
eventThread.interrupt()
var onStopCalled = false
try {
eventThread.join()
onStopCalled = true
onStop()
} catch {
case ie: InterruptedException =>
Thread.currentThread().interrupt()
if (!onStopCalled) {
onStop()
}
}
} else {
// Keep quiet to allow calling `stop` multiple times.
}
}
def post(event: E): Unit = {
if (!stopped.get) {
if (eventThread.isAlive) {
eventQueue.put(event)
} else {
onError(new IllegalStateException(s"$name has already been stopped accidentally."))
}
}
}
def isActive: Boolean = eventThread.isAlive
protected def onStart(): Unit = {}
protected def onStop(): Unit = {}
protected def onReceive(event: E): Unit
protected def onError(e: Throwable): Unit
}
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging {
private[this] val timer = dagScheduler.metricsSource.messageProcessingTimer
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}
// 真正处理事件的方法,通过模式匹配调用 DAGScheduler 对应的方法
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason)
case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val workerLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, workerLost)
case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}
override def onError(e: Throwable): Unit = {
logError("DAGSchedulerEventProcessLoop failed; shutting down SparkContext", e)
try {
dagScheduler.doCancelAllJobs()
} catch {
case t: Throwable => logError("DAGScheduler failed to cancel all jobs.", t)
}
dagScheduler.sc.stopInNewThread()
}
override def onStop(): Unit = {
dagScheduler.cleanUpAfterSchedulerStop()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
# 2.4 JobListener
JobListener 顾名思义就是 Job 的监听器,用以监听 Job 的成功与失败定义了监听器的接口和规范。如下:
private[spark] trait JobListener {
def taskSucceeded(index: Int, result: Any): Unit
def jobFailed(exception: Exception): Unit
}
2
3
4
Job 执行成功就调用taskSucceeded方法,失败则调用jobFailed方法。
JobListener 有两个实现类JobWaiter和ApproximateActionListener。前者用于等待整个 Job 执行完毕,然后调用给定的处理函数对返回结果进行处理(处理函数在构造器中指定)。而后者只对有单一返回结果的 Action(如 count、非并行的 reduce)进行监听。
private[spark] class JobWaiter[T](
dagScheduler: DAGScheduler,
val jobId: Int,
totalTasks: Int,
resultHandler: (Int, T) => Unit)
extends JobListener with Logging {
private val finishedTasks = new AtomicInteger(0)
private val jobPromise: Promise[Unit] =
if (totalTasks == 0) Promise.successful(()) else Promise()
def jobFinished: Boolean = jobPromise.isCompleted
def completionFuture: Future[Unit] = jobPromise.future
def cancel(): Unit = {
dagScheduler.cancelJob(jobId, None)
}
override def taskSucceeded(index: Int, result: Any): Unit = {
synchronized {
resultHandler(index, result.asInstanceOf[T])
}
if (finishedTasks.incrementAndGet() == totalTasks) {
jobPromise.success(())
}
}
override def jobFailed(exception: Exception): Unit = {
if (!jobPromise.tryFailure(exception)) {
logWarning("Ignore failure", exception)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
private[spark] class ApproximateActionListener[T, U, R](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
evaluator: ApproximateEvaluator[U, R],
timeout: Long)
extends JobListener {
val startTime = System.currentTimeMillis()
val totalTasks = rdd.partitions.length
var finishedTasks = 0
var failure: Option[Exception] = None
var resultObject: Option[PartialResult[R]] = None
override def taskSucceeded(index: Int, result: Any): Unit = {
synchronized {
evaluator.merge(index, result.asInstanceOf[U])
finishedTasks += 1
if (finishedTasks == totalTasks) {
resultObject.foreach(r => r.setFinalValue(evaluator.currentResult()))
this.notifyAll()
}
}
}
override def jobFailed(exception: Exception): Unit = {
synchronized {
failure = Some(exception)
this.notifyAll()
}
}
def awaitResult(): PartialResult[R] = synchronized {
val finishTime = startTime + timeout
while (true) {
val time = System.currentTimeMillis()
if (failure.isDefined) {
throw failure.get
} else if (finishedTasks == totalTasks) {
return new PartialResult(evaluator.currentResult(), true)
} else if (time >= finishTime) {
resultObject = Some(new PartialResult(evaluator.currentResult(), false))
return resultObject.get
} else {
this.wait(finishTime - time)
}
}
return null
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 3. DAGScheduler 源码分析
DAGScheduler 的源码有 2000 多行,猛一看着实让人头大,从上往下读实在是让人难受。我整理了一下,整体可以分为下面几部分分开去看:
- 第一部分当然是它的成员属性。具体每个属性的含义后面分析。
- 第二部分是提供给
SparkContext、TaskSetManager以及TaskScheduler调用的方法。如:submitJob、runJob、submitMapStage、taskStarted、taskGettingResult、taskEnded、executorLost、workerRemoved、executorAdded等,这里就不挨个列举了。这些方法的最终走向都是调用了 DAGSchedulerEventProcessLoop 的post方法,通过该方法向 DAGSchedulerEventProcessLoop 添加一个事件。 - 第三部分是提供给 DAGSchedulerEventProcessLoop 调用的一些
handle方法,当然并不一定是以handle作为前缀。DAGSchedulerEventProcessLoop 在消费 DAGSchedulerEvent 的过程中会通过模式匹配调用 DAGScheduler 提供的相应handle方法去处理。 - 第四部分是和 Stage 处理相关的方法。DAGScheduler 的核心作用就是 Stage 调度,所以肯定少不了和 Stage 相关的方法,如:
getOrCreateShuffleMapStage、createShuffleMapStage、createResultStage、getOrCreateParentStages。 - 除以上三种方法外,其它的方法都归为第五类。如:
executorHeartbeatReceived、getCacheLocs、checkBarrierStageWithRDDChainPattern、getShuffleDependencies。
# 3.1 DAGScheduler 工作流程
在分析 DAGScheduler 源码之前,先了解一下 DAGScheduler 的整体工作流程,方便后续源码分析。
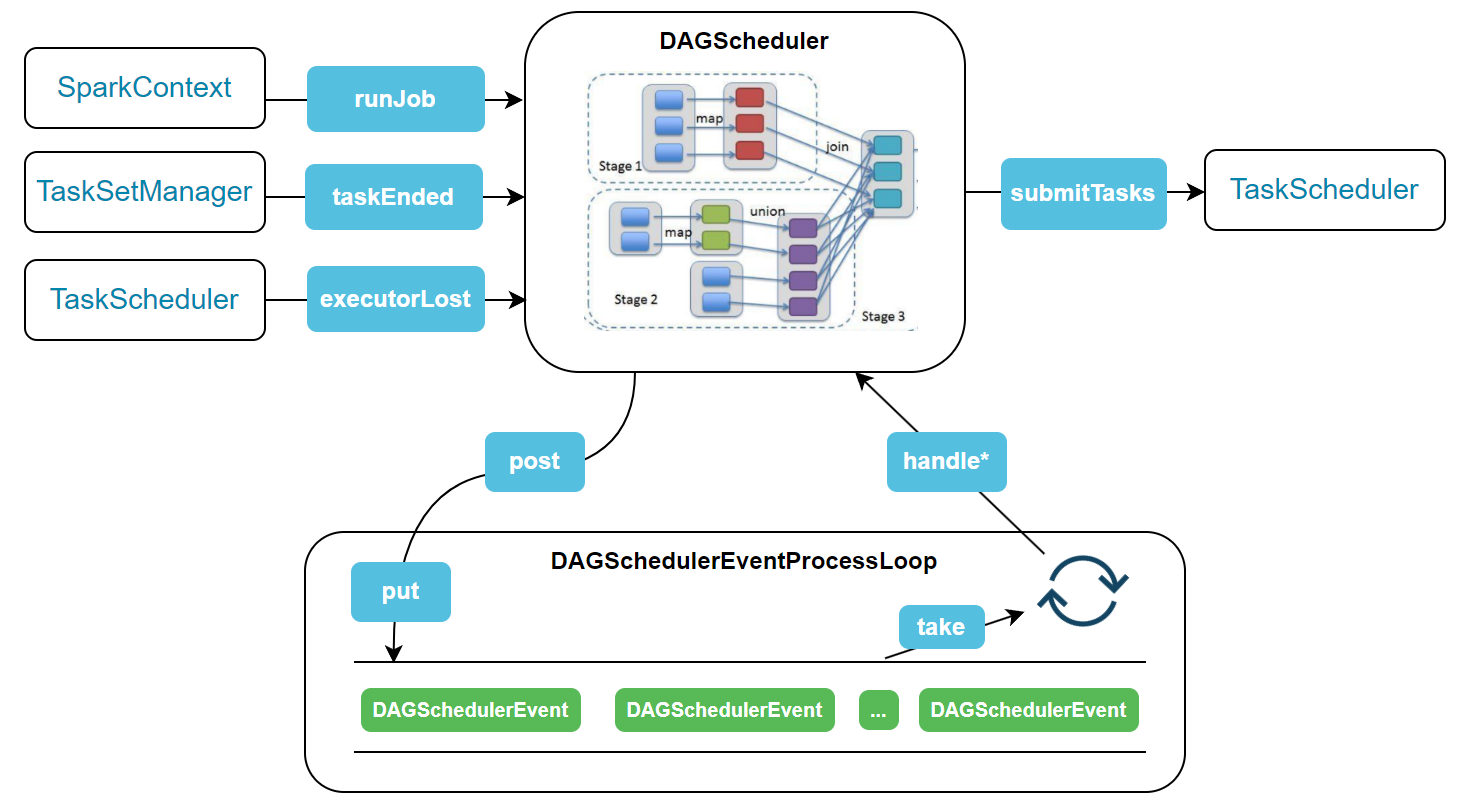
SparkContext、TaskSetManager以及TaskScheduler通过调用 DAGScheduler 提供的方法向 DAGScheduler 提交一个 DAGSchedulerEvent。- DAGScheduler 调用 DAGSchedulerEventProcessLoop 的 post 方法向其队列添加一个 DAGSchedulerEvent。
- DAGScheduler 在完成初始化之后,DAGSchedulerEventProcessLoop 中的轮询线程就一直在尝试从队列总获取 DAGSchedulerEvent。
- DAGSchedulerEventProcessLoop 获取到 DAGSchedulerEvent 之后通过模式匹配调用 DAGScheduler 对应的处理方法。
- DAGSchedulerEvent 的类型决定了接下来的调用信息,有些类型到第 4 步就已经结束了。但是有些事件(如 runJob)会继续调用 TaskScheduler 体提供的方法。
# 3.2 DAGScheduler 属性
private[spark] class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus, // 事件总线
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock() // 时钟对象
)
extends Logging {
def this(sc: SparkContext, taskScheduler: TaskScheduler) = {
this(
sc,
taskScheduler,
sc.listenerBus,
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster],
sc.env.blockManager.master,
sc.env)
}
def this(sc: SparkContext) = this(sc, sc.taskScheduler)
// DAGScheduler 的度量源
private[spark] val metricsSource: DAGSchedulerSource = new DAGSchedulerSource(this)
// 用于生成下一个 Job 的身份标识
private[scheduler] val nextJobId = new AtomicInteger(0)
// 总共提交的作业数量
private[scheduler] def numTotalJobs: Int = nextJobId.get()
// 下一个 Stage 的身份标识
private val nextStageId = new AtomicInteger(0)
// 用于缓存 JobId 与 StageId 之间的映射关系
private[scheduler] val jobIdToStageIds = new HashMap[Int, HashSet[Int]]
// 用于缓存 StageId 与 Stage 之间的关系
private[scheduler] val stageIdToStage = new HashMap[Int, Stage]
// 用于缓存 shuffleId 与 ShuffleMapStage 之间的映射关系
private[scheduler] val shuffleIdToMapStage = new HashMap[Int, ShuffleMapStage]
// 用于缓存 jobId 与 ActiveJob 之间的映射关系
private[scheduler] val jobIdToActiveJob = new HashMap[Int, ActiveJob]
// 处于等待阶段的 Stage(父 Stage 还未执行完)集合
private[scheduler] val waitingStages = new HashSet[Stage]
// 处于运行状态的 Stage 集合
private[scheduler] val runningStages = new HashSet[Stage]
// 处于失败状态的 Stage 集合
private[scheduler] val failedStages = new HashSet[Stage]
// 所有 ActiveJob 的集合
private[scheduler] val activeJobs = new HashSet[ActiveJob]
// 用于缓存每个 RDD 的所有分区的位置信息
private val cacheLocs = new HashMap[Int, IndexedSeq[Seq[TaskLocation]]]
// 当一个节点出现故障时,会将执行失败的 Executor 和 MapOutputTracker 当前的纪元添加到 failedEpoch
private val failedEpoch = new HashMap[String, Long]
private [scheduler] val outputCommitCoordinator = env.outputCommitCoordinator
private val closureSerializer = SparkEnv.get.closureSerializer.newInstance()
private val disallowStageRetryForTest = sc.getConf.get(TEST_NO_STAGE_RETRY)
private[scheduler] val unRegisterOutputOnHostOnFetchFailure =
sc.getConf.get(config.UNREGISTER_OUTPUT_ON_HOST_ON_FETCH_FAILURE)
// Stage 最大尝试次数
private[scheduler] val maxConsecutiveStageAttempts =
sc.getConf.getInt("spark.stage.maxConsecutiveAttempts",
DAGScheduler.DEFAULT_MAX_CONSECUTIVE_STAGE_ATTEMPTS)
// 每个 Job 检查失败的最大并行度
private[scheduler] val barrierJobIdToNumTasksCheckFailures = new ConcurrentHashMap[Int, Int]
private val timeIntervalNumTasksCheck = sc.getConf
.get(config.BARRIER_MAX_CONCURRENT_TASKS_CHECK_INTERVAL)
private val maxFailureNumTasksCheck = sc.getConf
.get(config.BARRIER_MAX_CONCURRENT_TASKS_CHECK_MAX_FAILURES)
// 只有一个线程的 ScheduledExecutor,职责是对失败的 Stage 进行重试
private val messageScheduler =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("dag-scheduler-message")
// 事件循环,在 DAGScheduler 完成初始化后会调用 eventProcessLoop 的 start 方法
private[spark] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
taskScheduler.setDAGScheduler(this)
// 省略中间方法代码。。。
eventProcessLoop.start()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
# 3.3 DAGScheduler 方法
DAGScheduler 方法相关的代码实在是太多了,所以就按照前面的分类看一些有代表性的。
# 3.3.1 注册事件相关
这部分方法是提供给SparkContext、TaskSetManager以及TaskScheduler调用的方法。如:submitJob、runJob、submitMapStage、taskStarted、taskGettingResult、taskEnded、executorLost、workerRemoved、executorAdded等,这里就不挨个列举了。这些方法的最终走向都是调用了 DAGSchedulerEventProcessLoop 的post方法,通过该方法向 DAGSchedulerEventProcessLoop 添加一个事件。
这部分代码里有些方法的实现是非常简单的,如:
// TaskSetManager 调用
def taskStarted(task: Task[_], taskInfo: TaskInfo): Unit = {
eventProcessLoop.post(BeginEvent(task, taskInfo))
}
// TaskSetManager 调用
def taskGettingResult(taskInfo: TaskInfo): Unit = {
eventProcessLoop.post(GettingResultEvent(taskInfo))
}
// TaskSetManager 调用
def taskEnded(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Seq[AccumulatorV2[_, _]],
metricPeaks: Array[Long],
taskInfo: TaskInfo): Unit = {
eventProcessLoop.post(
CompletionEvent(task, reason, result, accumUpdates, metricPeaks, taskInfo))
}
// TaskScheduler 调用
def executorLost(execId: String, reason: ExecutorLossReason): Unit = {
eventProcessLoop.post(ExecutorLost(execId, reason))
}
// TaskScheduler 调用
def workerRemoved(workerId: String, host: String, message: String): Unit = {
eventProcessLoop.post(WorkerRemoved(workerId, host, message))
}
// TaskScheduler 调用
def executorAdded(execId: String, host: String): Unit = {
eventProcessLoop.post(ExecutorAdded(execId, host))
}
// TaskSetManager 调用
def taskSetFailed(taskSet: TaskSet, reason: String, exception: Option[Throwable]): Unit = {
eventProcessLoop.post(TaskSetFailed(taskSet, reason, exception))
}
// TaskSetManager 调用
def speculativeTaskSubmitted(task: Task[_]): Unit = {
eventProcessLoop.post(SpeculativeTaskSubmitted(task))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
但是像submitJob和runJob的实现就稍微复杂一些:
// 用于提交一个 Job
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 获取当前 Job 的最大分区数
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
// 生成下一个 jobId
val jobId = nextJobId.getAndIncrement()
// 如果 partitions 为 0
if (partitions.isEmpty) {
val clonedProperties = Utils.cloneProperties(properties)
if (sc.getLocalProperty(SparkContext.SPARK_JOB_DESCRIPTION) == null) {
clonedProperties.setProperty(SparkContext.SPARK_JOB_DESCRIPTION, callSite.shortForm)
}
val time = clock.getTimeMillis()
// 向事件总线注册 Job 开始和结束两个事件
listenerBus.post(SparkListenerJobStart(jobId, time, Seq.empty, clonedProperties))
listenerBus.post(SparkListenerJobEnd(jobId, time, JobSucceeded))
// 返回一个等待 Job 完成的 JobWaiter
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.nonEmpty)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
// 返回一个等待 Job 完成的 JobWaiter
val waiter = new JobWaiter[U](this, jobId, partitions.size, resultHandler)
// 向 DAGSchedulerEventProcessLoop 注册 JobSubmitted 事件
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
Utils.cloneProperties(properties)))
waiter
}
// 运行一个 Job
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
// 先提交 Job,获取到一个 JobWaiter
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
// 等待监听的结果进行进一步处理
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# 3.3.2 处理事件相关
DAGSchedulerEventProcessLoop 在消费 DAGSchedulerEvent 的过程中会通过模式匹配调用 DAGScheduler 提供的相应 handle 方法去处理,这部分逻辑是在doOnReceive方法中。以处理JobSubmitted事件为例:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
// 调用了 DAGScheduler 的 handleJobSubmitted 方法
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
// 。。。
}
2
3
4
5
6
7
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit = {
var finalStage: ResultStage = null
try {
// 创建 ResultStage
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: BarrierJobSlotsNumberCheckFailed =>
// If jobId doesn't exist in the map, Scala coverts its value null to 0: Int automatically.
val numCheckFailures = barrierJobIdToNumTasksCheckFailures.compute(jobId,
(_: Int, value: Int) => value + 1)
logWarning(s"Barrier stage in job $jobId requires ${e.requiredConcurrentTasks} slots, " +
s"but only ${e.maxConcurrentTasks} are available. " +
s"Will retry up to ${maxFailureNumTasksCheck - numCheckFailures + 1} more times")
if (numCheckFailures <= maxFailureNumTasksCheck) {
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(JobSubmitted(jobId, finalRDD, func,
partitions, callSite, listener, properties))
},
timeIntervalNumTasksCheck,
TimeUnit.SECONDS
)
return
} else {
// Job failed, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId)
listener.jobFailed(e)
return
}
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
barrierJobIdToNumTasksCheckFailures.remove(jobId)
// ResultStage 创建成功之后,紧接着创建 ActiveJob
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
// 生成 Job 提交时间
val jobSubmissionTime = clock.getTimeMillis()
// 维护 jobId 与 ActiveJob 的映射关系
jobIdToActiveJob(jobId) = job
// 添加到 ActiveJob 集合中
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 最后提交 Stage
submitStage(finalStage)
}
// 提交 Stage
private def submitStage(stage: Stage): Unit = {
// 获取当前 Stage 对应的 JobId
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug(s"submitStage($stage (name=${stage.name};" +
s"jobs=${stage.jobIds.toSeq.sorted.mkString(",")}))")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 如果当前 Stage 同时满足:非等待状态、非运行状态、非失败状态
// 寻找父 Stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
// 如果不存在未提交的父 Stage,那么提交当前 Stage 中的 Task
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
// submitMissingTasks 中最终会提交到 TaskScheduler 中
submitMissingTasks(stage, jobId.get)
} else {
// 递归寻找未提交的父 Stage
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# 3.3.3 创建 Stage 相关
这是前面对 DAGScheduler 方法分类中的第三种。创建 Stage 相关的方法共有 4 个:
getOrCreateShuffleMapStagecreateShuffleMapStagecreateResultStagegetOrCreateParentStages
但是最核心的只有createResultStage和createShuffleMapStage,因为另外两个都是依赖于createShuffleMapStage:
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) =>
stage
case None =>
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
createShuffleMapStage(shuffleDep, firstJobId)
}
}
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
def createShuffleMapStage[K, V, C](
shuffleDep: ShuffleDependency[K, V, C], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, rdd.getNumPartitions)
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker)
stageIdToStage(id) = stage
shuffleIdToMapStage(shuffleDep.shuffleId) = stage
updateJobIdStageIdMaps(jobId, stage)
if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
logInfo(s"Registering RDD ${rdd.id} (${rdd.getCreationSite}) as input to " +
s"shuffle ${shuffleDep.shuffleId}")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# 3.3.4 其它方法
除了以上三类方法,第四类都是一下服务类的方法。如:
executorHeartbeatReceivedexecutorHeartbeatReceivedcheckBarrierStageWithRDDChainPatterncheckBarrierStageWithDynamicAllocationcheckBarrierStageWithNumSlots