Spark Task 源码分析
# 一、Task 概览
前面说过,在 Spark 中Application -> Job -> Stage -> Task每一层都是 1 对 n 的关系,也就是说 Task 是 Spark 中执行的最小单位,为了容错,每个 Task 可能会有一到多次任务尝试。Task 类关系图如下:
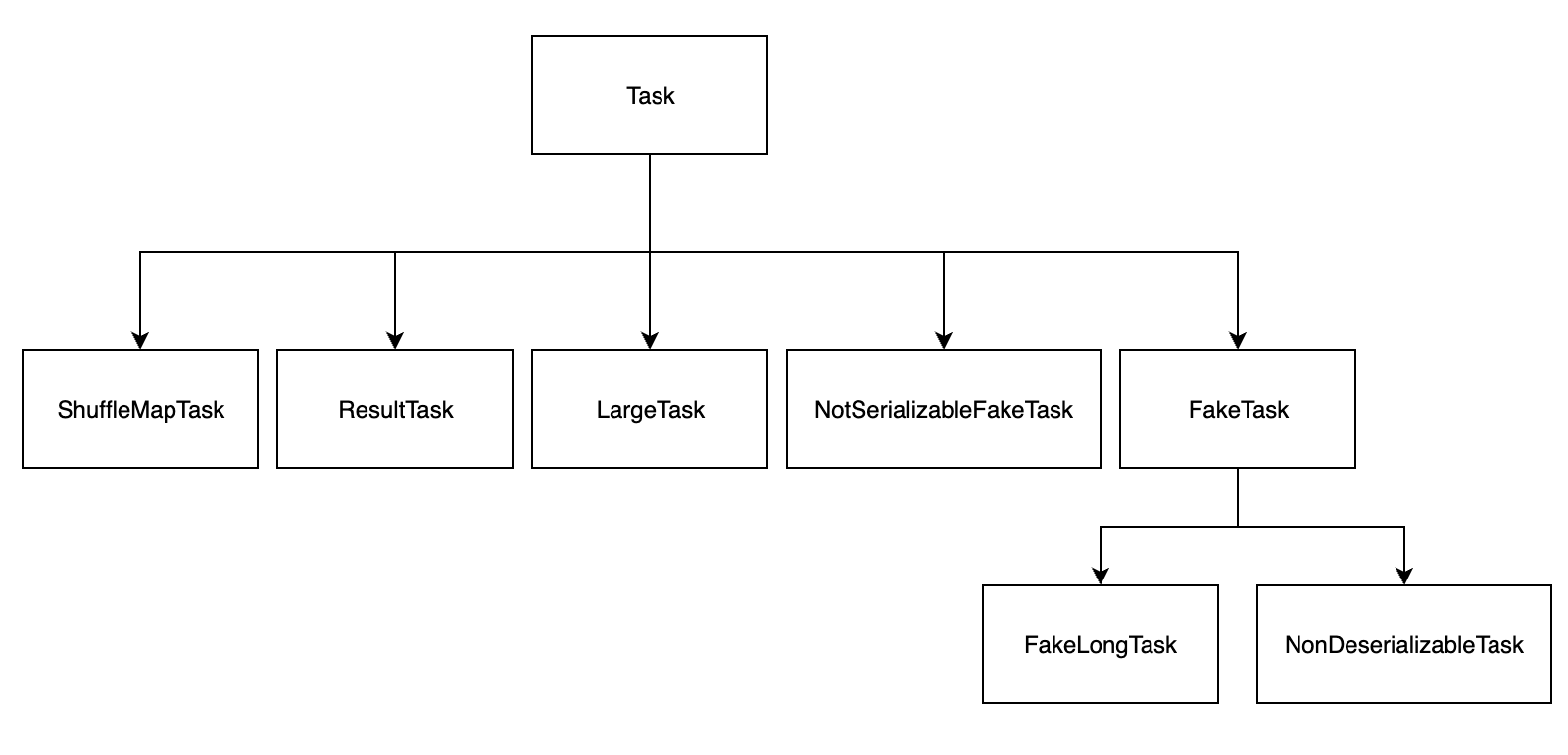
Task 是一个抽象类,它定义了一组 Task 的规范,其它子类都继承自 Task 类,Task的实现采用了模板方法设计模式。
在 Task 的七个子类中,重点关注 ShuffleMapTask 和 ResultTask。
ResultTask 只存在于最后一个 Stage 中,最后一个 Stage 之前的所有 Stage 中都是 ShuffleMapTask。ShuffleMapTask 执行任务并将任务输出分发到多个 bucket 中,ResultTask 执行任务后将其输出发送给 driver。
# 二、Task 源码
private[spark] abstract class Task[T](
val stageId: Int, // Task 所属的 Stage id
val stageAttemptId: Int, // Stage 尝试 id
val partitionId: Int, // Task 对应的分区 id
@transient var localProperties: Properties = new Properties, // Task 执行相关的属性
// 在 driver 端创建和序列化并发送到 executor 端的 TaskMetrics
serializedTaskMetrics: Array[Byte] =
SparkEnv.get.closureSerializer.newInstance().serialize(TaskMetrics.registered).array(),
val jobId: Option[Int] = None, // Task 所属的 Job id
val appId: Option[String] = None, // Task 所属的 Application id
val appAttemptId: Option[String] = None, // Task 所属的 Application 尝试 id
val isBarrier: Boolean = false) extends Serializable {
@transient lazy val metrics: TaskMetrics =
SparkEnv.get.closureSerializer.newInstance().deserialize(ByteBuffer.wrap(serializedTaskMetrics))
// 核心方法
// 执行 Task 的方法,由 org.apache.spark.executor.Executor 类调用
final def run(
taskAttemptId: Long, // Task 尝试 id
attemptNumber: Int, // 尝试次数,0 表示首次尝试
metricsSystem: MetricsSystem,
// Task 可以访问的资源信息,比如 gpu
resources: Map[String, ResourceInformation]): T = {
// 向 BlockManager 注册 Task 尝试
SparkEnv.get.blockManager.registerTask(taskAttemptId)
// 创建 Task 执行所需的上下文
val taskContext = new TaskContextImpl(
stageId,
stageAttemptId, // stageAttemptId and stageAttemptNumber are semantically equal
partitionId,
taskAttemptId,
attemptNumber,
taskMemoryManager,
localProperties,
metricsSystem,
metrics,
resources)
context = if (isBarrier) {
new BarrierTaskContext(taskContext)
} else {
taskContext
}
// 初始化文件名信息
InputFileBlockHolder.initialize()
// 将 Task 上下文保存为Thread Local类型(线程私有)
TaskContext.setTaskContext(context)
// 获取 Task 尝试的线程
taskThread = Thread.currentThread()
// 判断 Task 是否需要执行 kill() 方法
if (_reasonIfKilled != null) {
kill(interruptThread = false, _reasonIfKilled)
}
// 创建调用者上下文
new CallerContext(
"TASK",
SparkEnv.get.conf.get(APP_CALLER_CONTEXT),
appId,
appAttemptId,
jobId,
Option(stageId),
Option(stageAttemptId),
Option(taskAttemptId),
Option(attemptNumber)).setCurrentContext()
try {
// 调用子类实现的方法,因为 runTask() 在 Task 中是没有方法体的
runTask(context)
} catch {
case e: Throwable =>
// 捕获所有错误,运行任务失败回调,并重新抛出异常
try {
context.markTaskFailed(e)
} catch {
case t: Throwable =>
e.addSuppressed(t)
}
context.markTaskCompleted(Some(e))
throw e
} finally {
try {
// 调用任务完成回调。如果“markTaskCompleted”被调用两次,则第二次是空操作。
context.markTaskCompleted(None)
} finally {
try {
Utils.tryLogNonFatalError {
// 释放内存
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP)
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(
MemoryMode.OFF_HEAP)
val memoryManager = SparkEnv.get.memoryManager
memoryManager.synchronized { memoryManager.notifyAll() }
}
} finally {
TaskContext.unset()
InputFileBlockHolder.unset()
}
}
}
}
private var taskMemoryManager: TaskMemoryManager = _
def setTaskMemoryManager(taskMemoryManager: TaskMemoryManager): Unit = {
this.taskMemoryManager = taskMemoryManager
}
// 由子类实现,模板方法设计模式的体现
def runTask(context: TaskContext): T
// 获取当前 Task 偏好的位置信息
def preferredLocations: Seq[TaskLocation] = Nil
// MapOutputTracker 跟踪的纪元,由 TaskSetManager 设置,用于故障转移
var epoch: Long = -1
// task 上下文,在 run() 方法中初始化
@transient var context: TaskContext = _
// 运行任务的实际线程,如果为空的话,将在 run() 方法中初始化
@volatile @transient private var taskThread: Thread = _
// Task 被 kill 的原因。如果非空,则此任务已被终止。用于在调用 kill() 时上下文尚未初始化的情况。
@volatile @transient private var _reasonIfKilled: String = null
protected var _executorDeserializeTimeNs: Long = 0
protected var _executorDeserializeCpuTime: Long = 0
def reasonIfKilled: Option[String] = Option(_reasonIfKilled)
// 返回反序列化 RDD 和要运行的函数所花费的时间
def executorDeserializeTimeNs: Long = _executorDeserializeTimeNs
def executorDeserializeCpuTime: Long = _executorDeserializeCpuTime
// 收集此任务中使用的累加器的最新值。如果任务失败,则过滤掉其值不应包含在失败中的累加器
def collectAccumulatorUpdates(taskFailed: Boolean = false): Seq[AccumulatorV2[_, _]] = {
if (context != null) {
// Note: internal accumulators representing task metrics always count failed values
context.taskMetrics.nonZeroInternalAccums() ++
// zero value external accumulators may still be useful, e.g. SQLMetrics, we should not
// filter them out.
context.taskMetrics.externalAccums.filter(a => !taskFailed || a.countFailedValues)
} else {
Seq.empty
}
}
// kill 任务尝试线程,该函数是幂等的,可以多次调用
def kill(interruptThread: Boolean, reason: String): Unit = {
require(reason != null)
_reasonIfKilled = reason
if (context != null) {
context.markInterrupted(reason)
}
if (interruptThread && taskThread != null) {
taskThread.interrupt()
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
Task 抽象类中最核心的就是 run() 方法,run()方法虽然看着很长,但其实可以分为三部分来看。
- 第一部分是调用
runTask()之前的代码,虽然看着繁杂,但其实都是在做一些参数和依赖的初始化工作。 - 第二部分也是最核心的,就是执行调用
runTask(),但在Task类中该方法是没有方法体的,所以相当于调用的是其子类的实现。 - 第三部分就是在调用
runTask()之后的代码,其实就是在做异常处理的一些操作。
# 三、ShuffleMapTask 源码
ShuffleMapTask 继承自 Task 类,主要实现了 runTask()方法,源码如下:
private[spark] class ShuffleMapTask(
stageId: Int,
stageAttemptId: Int,
taskBinary: Broadcast[Array[Byte]],
partition: Partition,
@transient private var locs: Seq[TaskLocation],
localProperties: Properties,
serializedTaskMetrics: Array[Byte],
jobId: Option[Int] = None,
appId: Option[String] = None,
appAttemptId: Option[String] = None,
isBarrier: Boolean = false)
extends Task[MapStatus](stageId, stageAttemptId, partition.index, localProperties,
serializedTaskMetrics, jobId, appId, appAttemptId, isBarrier)
with Logging {
/** A constructor used only in test suites. This does not require passing in an RDD. */
def this(partitionId: Int) {
this(0, 0, null, new Partition { override def index: Int = 0 }, null, new Properties, null)
}
@transient private val preferredLocs: Seq[TaskLocation] = {
if (locs == null) Nil else locs.distinct
}
override def runTask(context: TaskContext): MapStatus = {
val threadMXBean = ManagementFactory.getThreadMXBean
// 反序列化相关的时间信息
val deserializeStartTimeNs = System.nanoTime()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
// 执行反序列化
val rddAndDep = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTimeNs = System.nanoTime() - deserializeStartTimeNs
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
val rdd = rddAndDep._1
// ShuffleDependency
val dep = rddAndDep._2
// While we use the old shuffle fetch protocol, we use partitionId as mapId in the
// ShuffleBlockId construction.
val mapId = if (SparkEnv.get.conf.get(config.SHUFFLE_USE_OLD_FETCH_PROTOCOL)) {
partitionId
} else context.taskAttemptId()
// 触发 RDD 计算并输出
dep.shuffleWriterProcessor.write(rdd, dep, mapId, context, partition)
}
override def preferredLocations: Seq[TaskLocation] = preferredLocs
override def toString: String = "ShuffleMapTask(%d, %d)".format(stageId, partitionId)
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 四、ResultTask 源码
ResultTask 是只存在于最后一个 Stage 中,同样继承了 Task 并实现了runTask()方法。ResultTask 会将执行结果发送给 driver。源码如下:
private[spark] class ResultTask[T, U](
stageId: Int,
stageAttemptId: Int,
taskBinary: Broadcast[Array[Byte]],
partition: Partition,
locs: Seq[TaskLocation],
val outputId: Int,
localProperties: Properties,
serializedTaskMetrics: Array[Byte],
jobId: Option[Int] = None,
appId: Option[String] = None,
appAttemptId: Option[String] = None,
isBarrier: Boolean = false)
extends Task[U](stageId, stageAttemptId, partition.index, localProperties, serializedTaskMetrics,
jobId, appId, appAttemptId, isBarrier)
with Serializable {
@transient private[this] val preferredLocs: Seq[TaskLocation] = {
if (locs == null) Nil else locs.distinct
}
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
// 反序列化的时间信息
val deserializeStartTimeNs = System.nanoTime()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
// 执行反序列化
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTimeNs = System.nanoTime() - deserializeStartTimeNs
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
// 进行迭代计算和最终处理
func(context, rdd.iterator(partition, context))
}
// This is only callable on the driver side.
override def preferredLocations: Seq[TaskLocation] = preferredLocs
override def toString: String = "ResultTask(" + stageId + ", " + partitionId + ")"
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
上次更新: 2023/11/07, 07:39:51